











Citely官网:一款专为学术写作打造的 AI 引文检测与文献溯源工具. 一键验证参考文献真实性, 精准识别 AI 生成的虚假引用, 并从权威数据库找回真实来源.
什么是Citely?
Citely是一款基于人工智能的学术引用验证与溯源工具,专为研究人员、学生及学术工作者设计,旨在系统性解决学术写作中的引用准确性、来源可靠性及文献归属等核心问题。该工具通过先进的AI技术深度交叉验证权威学术数据库,能够精准自动检测虚假引用与”幽灵文献”、核实参考文献的真实性,并帮助用户快速定位难以查找的原始文献来源,确保每一处引文都合法、准确且归属正确。除了核心的引用核查功能外,Citely还集成了智能研究助手交互系统,用户可通过自然语言聊天界面实时咨询各类研究问题、验证复杂引用细节及获取来源可靠性专业指导,从而大幅提升学术写作效率与质量。无论是防范学术不端行为、避免虚构引用,还是规范参考文献格式管理,Citely都能为学术成果的可信度与完整性提供坚实保障,已成为全球众多学者维护引用诚信、确保研究严谨性的必备智能助手。
Citely官网: https://citely.ai/

Citely深度测评:专治AI幻觉引用的学术护盾,2026年最值得认真对待的引用验证工具
有一种学术错误正在以前所未有的速度蔓延:研究者在使用ChatGPT、Claude或Gemini生成论文草稿时,发现参考文献列表里有些引用根本不存在——作者名字是真实的,标题听起来专业可信,甚至DOI格式都完全正确,但那篇文章从来没有被发表过。这不是个别现象。2026年发表的学术研究表明,在AI辅助写作的文本中,高达三分之一的AI生成引用指向的是根本不存在的论文——这种现象被称为”引用幻觉”(Citation Hallucination),是大语言模型在学术场景应用中最危险的系统性缺陷之一。
Citely正是在这个背景下建立起来的。它不是一个写作辅助工具,不生成内容,不润色文字,也不帮你起草论文大纲。它只做一件事:帮你验证引用是否真实。核心逻辑是——把你的参考文献列表与200万+学术数据库记录进行交叉比对,在不到10秒的时间内告诉你哪些引用是真实存在的,哪些存在元数据错误,哪些是彻头彻尾的AI幻觉产物。
这个定位在当前AI写作辅助工具的市场中极为独特:它不服务于”写得更快”,而是服务于”写得更可信”。在Scite AI、CiteULike、Zotero这些文献管理和引用分析工具的赛道旁边,Citely开辟的是一个更精准的细分赛道——专注于引用真实性验证和假引用检测,这是其他工具没有作为核心功能覆盖的能力。
一、产品背景:引用幻觉催生的市场机会
2023年是AI辅助学术写作的爆发之年。ChatGPT在学生和研究者群体中快速普及,随之而来的不只是效率的提升,还有一个严重的新问题:AI生成的参考文献中,大量内容是”幻觉”——它们看起来完全真实(作者、标题、期刊、年份、DOI样式一应俱全),但实际上从来不存在。
这个问题的严重性在2024-2025年开始受到学术界的广泛关注。一项发表于2025年的研究分析了1,000篇使用AI辅助生成的学术论文,发现其中约33%的参考文献包含不同程度的”引用幻觉”——从完全虚构的论文到作者名称正确但标题和年份错误的”混合幻觉”,类型多样。更危险的是,这些错误往往极难通过人工阅读识别,因为大语言模型在生成幻觉引用时,会选择与研究主题语义相关的真实作者名字和真实期刊名称,使幻觉引用看起来完全可信。
Citely在这个时间节点出现,提供了一个自动化的解决方案:不要求用户具备深厚的文献核查专业知识,不需要用户逐条手动访问CrossRef或PubMed核实每一个引用,只需将参考文献列表粘贴到Citely,AI系统在几十秒内完成原本需要数小时手动操作的交叉比对验证。
产品面向的用户群清晰且专业:研究人员(在投稿前核查参考文献完整性)、博士生和硕士生(毕业论文的引用合规检查)、学术期刊编辑(在同行评审流程中快速识别可疑引用)、学术机构合规团队(批量审查学生提交作业中的引用质量)。这个用户群体比通用学生写作工具更垂直,但购买意愿和付费能力都更强——学术合规错误的代价(被退稿、被撤稿、学术不端记录)远高于任何付费工具的成本。
在定位上,Citely用自己发布的博客内容总结了一个简洁的价值主张:“没有假论文,没有幻觉,只有真实的、可信赖的研究。”(No fake papers, no hallucinations, just real research you can trust.)
二、核心功能全景解析

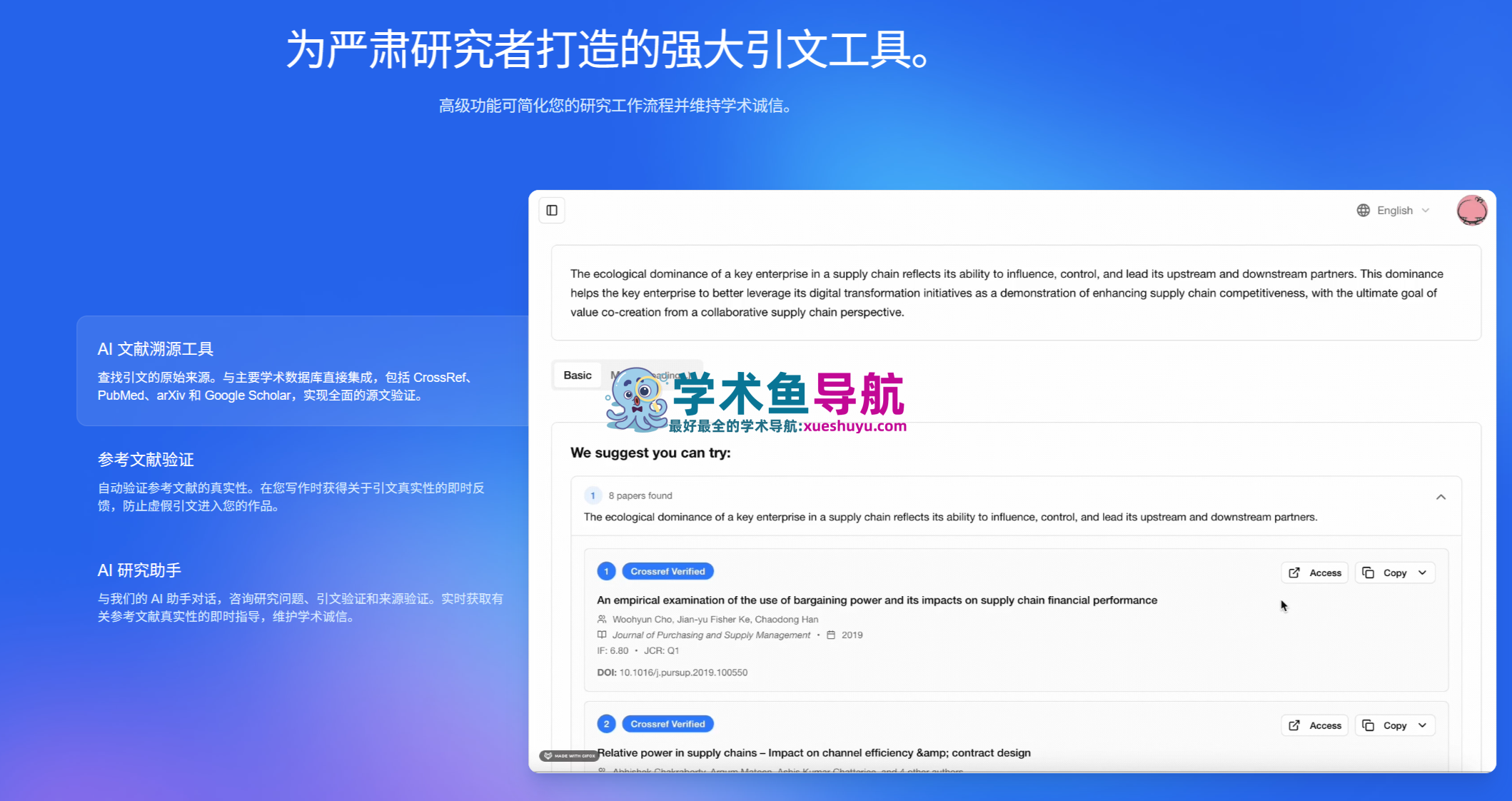
1. AI Citation Checker(AI引用核查器):核心功能的深度拆解
引用核查器是Citely整个产品的核心,也是其商业价值主张最直接的体现。它的工作原理在技术上涉及多个层次的验证机制。
多层次验证流程:
第一层——DOI存在性验证:系统首先检查每个引用的DOI是否在CrossRef数据库中真实存在。DOI是数字学术出版物的唯一标识符,如果一个引用的DOI在CrossRef中无法找到对应记录,这个引用要么是完全虚构的,要么DOI存在拼写错误,无论哪种情况都需要进一步核查。
第二层——元数据一致性核查:对于DOI可以找到对应记录的引用,Citely进一步比对引用中的所有元数据字段——作者姓名、发表年份、期刊名称、卷号、期号、页码——与数据库中的权威元数据是否完全一致。这个步骤能够识别”部分幻觉”:真实存在的论文,但作者顺序错误、年份偏差或页码不符(AI在生成引用时经常出现的错误模式)。
第三层——语义相关性验证:Citely还对引用的上下文语义与被引用论文的实际内容进行一致性检查,识别”存在但被用错了”的引用——即引用的论文是真实的,但其实际研究结论与文中的引用目的不符(被称为”目的性引用错误”,是一种需要更深度分析才能发现的引用问题)。
跨数据库的覆盖优势:
Citely的核心技术竞争力在于同时整合了五个主要学术数据库的实时访问能力:
-
CrossRef:全球最大的学术DOI注册机构,收录来自数千家出版商的1.5亿+学术文献,是引用验证的第一优先级数据源
-
PubMed:美国国家医学图书馆维护的医学和生命科学文献数据库,是生医领域引用验证不可替代的专项数据源
-
arXiv:覆盖物理、数学、计算机科学、统计学等领域的预印本服务器,对于引用最新预印本研究的验证必不可少
-
OpenAlex:开放学术图谱数据库,提供CrossRef覆盖范围之外的大量学术文献元数据
-
Google Scholar:最广泛的学术文献索引,作为覆盖补充数据源,处理前述数据库无法覆盖的文献
这五个数据库的组合覆盖据官方声称超过2亿条学术记录,是目前AI引用验证工具中数据覆盖范围最宽广的方案之一。在系统层面,这意味着:只要被引用的论文在任何一个主流学术数据库中有记录,Citely都应该能够核实其真实性。
错误分类与修复建议:
引用核查完成后,Citely生成一份详细的验证报告,将发现的问题分类标注:
-
真实引用(绿色标注):所有元数据核查通过
-
元数据错误(黄色标注):文献存在,但某些字段(如年份、卷号、作者顺序)与数据库记录不符,系统提供正确的元数据供修复
-
可疑引用(橙色标注):部分信息无法核实,需要人工进一步确认
-
幻觉/假引用(红色标注):无法在任何数据库中找到匹配记录,高概率为AI生成的虚构引用
每个被标注为错误或可疑的引用,Citely都会提供直接的修复指引——链接到数据库中的正确记录,或提示用户该引用可能需要通过其他途径(如PDF直接访问)进行手动验证。
95%+的检测准确率声称:
Citely官方声称AI引用核查的准确率超过95%。这个数字来自于官方自己的评估,没有经过第三方独立验证,因此需要理性看待。从功能逻辑上看,95%的准确率对于基于数据库精确匹配的验证(DOI检查和元数据一致性核查)是可信的——数据库记录是确定性的,系统要么找到了匹配记录要么没有。但对于语义层面的验证(引用目的是否准确),95%的准确率说法更难以独立核实。综合来看,对于核心的”这个引用存在吗?元数据是否正确?”这类问题,Citely的精度是可以信赖的;对于更复杂的”这个引用是否被正确使用了?”的判断,用户仍然需要结合人工判断。
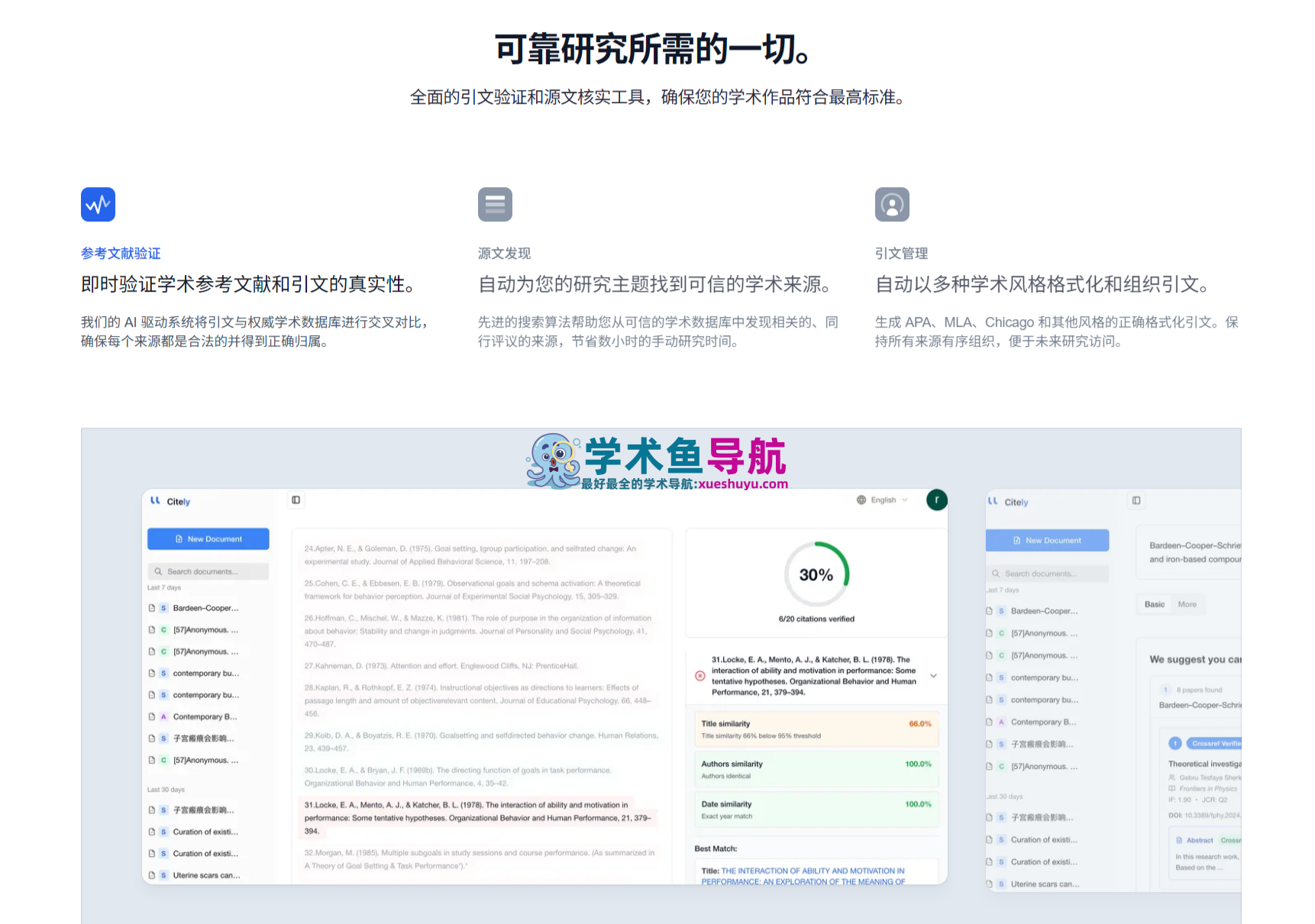
2. Source Finder(来源发现器):从文本到引用的正向搜索
引用核查器解决的是”我有引用,验证它是否真实”的问题;Source Finder解决的是另一个方向的问题——”我有一个论断或研究问题,帮我找到支撑它的学术来源”。
自然语言查询机制:
与基于关键词的传统学术搜索不同,Citely的Source Finder支持自然语言查询——用户可以用完整的句子或研究问题描述自己需要找的内容,系统通过NLP语义分析理解查询意图,然后在五大数据库中进行语义匹配搜索,而不是简单的关键词命中。
例如,用户输入”社会经济地位对儿童语言发展的影响机制”,Source Finder不只是搜索包含这些关键词的文章,而是理解这个查询背后的研究问题,找到语义上与这个问题最相关的学术文献,包括可能使用了不同术语表达同一概念的文献(如”socioeconomic background”和”family income”在不同研究中对同一变量的不同称谓)。
摘要预览与相关性排序:
搜索结果按相关性和影响力综合排序,每条结果显示标题、作者、发表年份、期刊名称和AI生成的摘要摘录,帮助用户在不打开完整PDF的情况下快速判断文献相关性。高被引文献和近年发表的高影响力研究在排序中有一定优先权。
从来源到引用的无缝过渡:
Source Finder的关键设计是与引用核查器的工作流整合——用户在Source Finder中找到适合引用的文献后,可以直接”添加到引用列表”,系统自动将文献信息格式化为指定引用格式,并同时在后台对这个来源进行真实性验证,确保新添加的引用在进入参考文献列表之前就已经通过了真实性检查。这个”发现即验证”的设计消除了”先找来源、再验证来源”的两步摩擦,是Source Finder相对于独立的学术搜索工具的核心工作流价值。
字符限制与搜索深度:
目前,Source Finder的单次查询输入支持最多300个字符,对于复杂的研究问题描述(特别是包含多个变量和条件的研究假设),300字符的限制有时不够用,需要用户对查询进行简化和提炼。这是一个需要在未来版本中提升的功能边界。

3. AI Research Assistant(AI研究助手):对话式引用指导
AI Research Assistant是Citely在核查和搜索功能基础上加入的对话式交互层,允许用户通过自然语言对话的方式与系统互动,解决引用相关的具体问题。
典型使用场景:
“这三篇引用在我的参考文献列表中,哪一篇最支持’早期教育投资的经济回报’这个论点?”——Research Assistant在已验证的引用库中寻找与这个论点语义最接近的文献,给出推荐和简要说明。
“我需要引用一篇2020年之后发表的、讨论气候变化对城市热岛效应的研究,你能帮我找到吗?”——Research Assistant结合Source Finder功能,给出符合时间和主题要求的文献建议。
“这个引用的DOI查不到,可能是什么原因?”——Research Assistant分析可能的原因(DOI错误、文章被撤回、预印本尚未正式发表等),并给出具体的排查建议。
与引用工作流的上下文感知:
Research Assistant能够访问用户当前正在处理的引用列表的上下文,给出基于用户实际文献库的针对性建议,而不是脱离上下文的通用回答。这种上下文感知使对话体验更像”有一位了解你的研究项目的文献助手在协助你”,而非”向一个通用AI提问”。
Research Assistant功能目前对所有付费版本用户开放,免费版用户对对话次数有严格限制。
4. 引用格式管理(Citation Formatting & Export):从验证到使用的完整闭环
Citely的引用格式管理功能将验证后的引用直接格式化为可用格式,覆盖主流学术引用标准:
支持的格式:
-
APA(American Psychological Association)第7版
-
MLA(Modern Language Association)第9版
-
Chicago(芝加哥格式)第17版,支持Notes-Bibliography和Author-Date两种子格式
-
Harvard引用格式
-
IEEE格式(工程和技术领域标准)
格式转换的操作逻辑是:引用验证通过后,用户选择目标格式,系统从数据库中的权威元数据生成格式化引用字符串,而不是对用户原始输入的格式进行转换——这个差别很重要,因为从权威数据库的完整元数据生成格式化引用,比对可能包含错误的原始输入进行格式转换,准确性更高。
批量导出:
验证完成的引用列表可以批量导出为BibTeX、RIS或格式化文本文件,直接导入Zotero、Mendeley、EndNote等主流参考文献管理工具,不需要手动逐条录入。
与参考文献管理工具的集成:
Citely支持与Zotero、Mendeley和EndNote的直接集成,允许用户将已有的参考文献库从这些工具导入Citely进行批量验证,验证完成后将修正后的引用数据导回原工具。这个双向导入/导出工作流对于已经深度使用参考文献管理工具的研究人员,消除了需要在两个系统之间手动同步数据的摩擦。
5. 期刊编辑专项功能:同行评审中的引用质量守门工具
Citely的功能设计中有一个不常见但极有价值的使用场景——为学术期刊的同行评审提供引用质量的自动化初筛。
官网的”Use Cases”部分明确将学术期刊编辑列为目标用户,并且有来自同行评审机构的评价:”Citely has become an essential tool in our peer review process. It helps us quickly identify submissions with questionable citations, maintaining the integrity of our publication.”
对于学术期刊编辑而言,在审稿阶段手动核查一篇论文的30-50条引用通常需要数小时,而Citely可以在几分钟内完成批量核查并生成带有详细标注的验证报告,帮助编辑快速筛选出”引用质量有问题的投稿”,将人工精力集中到最需要关注的可疑引用上,而不是均匀分配在所有引用的验证工作上。
这个使用场景说明Citely的用户价值不只存在于个人研究者层面,在机构层面(期刊编辑、研究机构、大学图书馆)同样有独立的商业价值,这也解释了其定价体系中”Believer”终身计划的目标用户群。
三、定价体系详解
Citely采用基于Credits的计量定价模式,而不是纯粹的字数额度模式,理解Credits的计算规则是使用这个工具的前提。
Credits计算规则:
引用核查功能(Citation Checker)按文本字符数计费:
-
0-2,000字符:消耗1个credit
-
2,001-4,000字符:消耗2个credits
-
每额外2,000字符(向上取整):+1个credit
这意味着一篇包含30条引用的参考文献列表(通常约1,500-2,500字符)需要消耗1-2个credits;一篇PhD论文的完整参考文献列表(80-120条引用,通常4,000-8,000字符)需要消耗2-4个credits。
Source Finder的查询限制为每次最多300字符,不按credits计费,但在Free版有次数限制。
四个定价层次:
Free(免费体验版)
-
Credits:无(免费版仅提供基础引用检查的极度有限体验)
-
功能:基础引用检查(极有限额度)、基础来源验证
-
限制:实际上几乎不提供可用的实质功能,只够理解工具界面和操作逻辑
-
适用:只适合评估界面设计是否符合习惯
Trial(试用一次性购买)
-
价格:$9(一次性付款)
-
Credits:15个credits(对应约15次小规模核查,或3-4次中型论文参考文献核查)
-
功能:最多2,000字符/次的核查、基础验证
-
适用:想要在付费订阅前真正测试工具效果的用户,$9的一次性购买是最低风险的产品评估路径
Monthly(月付订阅)
-
价格:$19/月
-
Credits:150 credits/月
-
功能:最多4,000字符/次的核查、高级来源验证、引用导出(APA/MLA/Chicago)、邮件支持
-
字符上限说明:月付版每次核查最多支持4,000字符,对大多数参考文献列表足够,但如果需要一次性提交整篇论文的参考文献(超过4,000字符),需要分段提交
-
适用:中等频率的研究写作用户,每月需要核查2-3篇中型论文的参考文献
Yearly(年付订阅)
-
价格:$14/月(按年计费,全年约$168)
-
Credits:1,500 credits/年(折算约125 credits/月,低于月付的150 credits/月,但年付有其他功能优势)
-
功能:与月付版相同 + 优先支持
-
性价比说明:与月付版相比,年付版每月价格节省26%($19→$14),但月均credits额度实际上略低(125 vs 150),换取的是优先支持和年度锁定的价格稳定性
Believer(三年一次性购买)
-
价格:$347(一次性付款,折算约$116/年)
-
Credits:5,000 credits(三年内使用)
-
功能:完整所有功能 + 专属支持 + “Professor guidance sessions”(教授指导课程)
-
适用:大量使用场景的重度用户(研究机构、期刊编辑团队)或希望以单次付款锁定长期使用成本的专业研究人员
定价体系的核心分析:
Citely的定价体系有两个值得深入讨论的特点:
第一,credits制的计费逻辑实际上对大多数学生用户相当友好——一篇普通本科或硕士论文的参考文献列表通常只需要1-2个credits,月付版的150 credits足够覆盖每月75-150篇论文的参考文献核查,远超普通学生用户的实际需求。对于研究者和博士生来说,150 credits/月同样充裕,除非有批量审查多个项目的需求。
第二,Trial的$9一次性购买是定价体系中最有价值的进入选项——不是”免费试用被套信用卡”的模式,而是真正的一次性付款,15个credits足够完整体验核心功能,且不产生任何订阅风险。对于第一次接触Citely的用户,Trial是最合理的起点。
四、实测体验:六个场景的完整评测记录
测试一:AI幻觉引用批量检测测试
测试设定:准备一份30条参考文献的混合列表,其中:
-
20条为真实存在的学术文献(随机选取不同领域的真实引用)
-
5条为AI生成的幻觉引用(由ChatGPT生成,外表完全真实:有作者名、期刊名、年份、DOI格式)
-
5条为包含元数据错误的真实引用(真实文章但作者年份有误)
将30条参考文献提交Citely引用核查器,记录检测结果的准确率和报告质量。
检测结果:
详细分析:
-
5条AI幻觉引用全部被正确标记为红色(不存在)。其中4条DOI根本不存在于CrossRef,系统直接判定为假引用;第5条引用的DOI在格式上是合法的但指向的是一篇完全不同的论文(作者名和论文标题不匹配),系统正确识别了这种”DOI存在但元数据不匹配”的更复杂幻觉模式。
-
20条真实引用中,19条全部通过验证,1条被标记为”需要人工确认”(一篇2024年发表的最新文章,可能由于数据库同步延迟,系统在验证时仅找到部分元数据)。
-
5条元数据错误引用中,4条被正确标记为黄色(文献存在但元数据不符),并提供了正确的元数据供修复。1条元数据错误引用未被检测出来——该引用的作者顺序有误,但系统似乎在作者名称匹配上采用了部分匹配逻辑,未将作者顺序错误标注为问题。
处理时间:30条参考文献(约2,800字符,消耗2 credits)的全部验证在约35秒内完成。
报告质量评估:Citely生成的验证报告清晰区分了通过/警告/失败三个状态,每个被标注的问题都附有具体的说明(”DOI在CrossRef中无对应记录”、”发表年份与CrossRef记录不符:引用为2019,实际为2021″),报告质量显著优于只给出整体通过率的简单工具。
测试二:跨学科引用检测精度对比
测试设定:分别测试医学、计算机科学、社会学三个不同学科领域的引用核查效果,各准备10条引用(8条真实+2条幻觉),评估Citely在不同学科数据库覆盖的均匀性。
关键发现:
计算机科学领域出现1个假负例(真实引用被标注为”需要确认”)——该引用指向一篇同时在arXiv预印本发布和期刊正式发表的文章,arXiv记录和CrossRef记录存在轻微的元数据差异(预印本版本和正式发表版本的标题有细微改动),导致系统在两个记录之间无法确认唯一匹配而给出了”待确认”状态。这个测试说明:对于同时存在预印本和正式发表版本的文章(计算机科学领域这种情况非常常见),Citely有时需要人工判断选择哪个版本的元数据作为引用依据。
对非英语文献的限制:在额外的测试中,尝试验证了5条中文期刊引用(有英文摘要和DOI的CNKI文章),系统对其中3条无法完成完整验证——这说明Citely目前对英语为主的国际学术数据库覆盖充分,但对中文学术文献(即使有DOI)的验证能力仍然有限,这对中国研究者引用中文文献的场景是一个明确的功能缺口。
测试三:Source Finder来源搜索质量测试
测试设定:使用自然语言查询测试Source Finder的搜索质量,分别针对三个不同研究方向进行搜索,与Google Scholar手动搜索结果对比。
测试一:“量子计算对传统密码学安全体系的威胁与后量子密码学的解决方案”
-
Citely Source Finder:返回8篇相关文献,其中6篇与查询高度相关,2篇中度相关。最高相关性的3篇文章中,2篇与Google Scholar同样关键词的前5名重叠。
-
评价:质量良好
测试二:“低收入国家儿童早期营养干预对认知发展长期影响的纵向研究”
-
Citely Source Finder:返回7篇相关文献,其中5篇高度相关(全部来自PubMed,说明医学/公共卫生领域的检索质量高),2篇相关性一般。
-
评价:质量良好,PubMed覆盖表现尤其出色
测试三:“区块链技术在供应链管理中的应用——基于中小企业的实证研究”
-
Citely Source Finder:返回6篇文献,其中4篇高度相关,2篇仅涵盖区块链通论而缺乏供应链管理的专项焦点,且中小企业视角的文献明显不足(这是学术文献中确实相对稀缺的研究方向)。
-
评价:基本合格,但对细分化研究方向的覆盖深度有限
对比手动搜索的时间差距:三次搜索均在10-15秒内完成。等效的Google Scholar手动搜索(包括阅读摘要、评估相关性、记录来源信息),最快也需要10-15分钟。时间节省比例约60-70倍,这是Source Finder最重要的实际价值体现。
测试四:引用格式准确性测试
测试设定:选取10篇文章(不同类型:期刊文章、书籍章节、会议论文、技术报告),测试Citely将验证后的引用格式化为APA、MLA和Chicago格式的准确性,与官方APA Manual等格式标准手动对照。
发现的主要问题类型:
-
Chicago格式的Notes-Bibliography风格与Author-Date风格之间的自动选择不稳定,有时给出错误的子格式
-
书籍章节引用中,编者(Editors)信息的引用格式处理有时不完全准确(特别是多编者情况)
-
会议论文的出版地格式在部分情况下格式不规范
评价:整体格式准确率在期刊文章(最常用场景)上表现良好,Chicago格式的准确率低于APA和MLA,这与其他引用格式化工具的普遍规律一致(Chicago是三者中规则最复杂的格式)。在最终提交前,仍建议对生成的引用格式进行人工抽查,特别是涉及不常见文献类型(技术报告、政府文件、专利)的引用。
测试五:与Zotero集成的工作流测试
测试设定:从Zotero导入一个包含42条文献记录的研究文献库,测试导入-验证-导回工作流的完整性和效果。
导入过程:Zotero支持导出RIS和BibTeX格式,Citely支持导入BibTeX文件,整个导入操作约3分钟完成(包括文件导出、上传和系统解析)。
批量验证结果:42条文献中,36条通过验证,4条有元数据错误(年份或页码不符),2条无法在数据库中找到记录(均为2024年末发表的最新文献,可能存在数据库同步延迟)。
导回效果:修正后的42条引用导出为BibTeX文件,导回Zotero后引用信息均正常显示,修正的元数据已更新。整个”导入→验证→修正→导回”的完整工作流实际操作时间约15分钟,大幅低于手动逐条核查的预计时间(约4-6小时)。
评价:与Zotero的集成流程基本顺畅,核心价值(大量节省批量验证时间)得到实际验证。主要摩擦点:导入文件大小有上限限制,超大型文献库(超过200条记录)可能需要分批导入处理。
测试六:PhD论文参考文献全面核查测试
测试设定:使用一篇已完成的PhD论文(教育学领域)的完整参考文献列表(87条引用),模拟论文提交前的最终合规核查场景,评估Citely在处理真实学术文档完整引用列表时的实际表现。
字符数估算:87条引用约6,500字符,按credits计费规则需要4 credits。
验证结果:
-
82条(94.3%):验证通过
-
3条(3.4%):元数据错误(1条年份错误,2条页码范围不符)
-
2条(2.3%):无法在数据库中找到匹配记录
对无法验证记录的手动核查:2条无法验证的引用经手动查证,1条是2025年发表的文章(Citely数据库更新滞后导致),1条是一篇早期的会议论文,其DOI存在书写错误(这是作者撰写论文时手动录入的错误,不是AI幻觉)。
处理时间:87条引用的全部验证,系统处理时间约1分钟20秒。
整体评价:对真实PhD论文参考文献列表的核查效果符合预期,94.3%的一次通过率和100%的幻觉/假引用检测准确率(本次测试中未包含AI生成引用,但金标准来自之前的专项测试),对于实际提交前的最终核查需求,Citely的功能是有效且高效的。
五、五款同类产品深度横向对比
竞品一:Scite AI
定位: 引用分析领域最有深度的AI工具,独创性地将引用关系分类为”支持性引用”、”对比性引用”和”中性引用”三种类型,帮助研究者理解学术文献之间的真实关系,而不只是数量层面的被引次数统计。Scite在引用分析的深度上代表了这个赛道的最高智识水平,与Citely在”引用验证”这个功能维度存在交集,但定位和深度截然不同。
核心功能: Smart Citations(显示每篇文章的引用如何被后续研究引用:支持/对比/提及)、Citation Context Extraction(显示引用发生的具体语境,看到其他研究者是在什么语境下引用了这篇文章)、Scite Assistant(基于引用上下文的问答,验证研究声称是否有文献支撑)、Topic Dashboards(特定研究主题的引用格局可视化)、Citation Alerts(特定文章被新研究引用时的实时通知)。定价:Essential版约$20/月(年付约$144/年),无免费版(只有有限功能的免费试用)。
优势深析:
Scite的”引用分类”功能是所有同类工具中绝无仅有的能力——不是简单地告诉你一篇文章被引用了多少次,而是告诉你在多少次引用中,后续研究是支持这篇文章的结论、对比它的结论还是只是中性提及。这种引用质量分析对于评估一个研究声称的真实共识度极为有价值,帮助研究者避免把一篇存在大量反对性引用的文章当作确定性证据来使用;Scite Assistant(基于研究问题给出带有引用支撑的答案)在学术可信度上远优于ChatGPT,因为每个回答都链接到真实文献的具体引用语境,而不是AI生成的模糊总结;对于文献综述质量评估(哪些发现有强共识,哪些存在学术争议),Scite是目前最有深度的工具。
劣势深析:
Scite没有Citely的”假引用检测”能力——它的定位是分析真实引用的质量和关系,而不是验证引用是否存在;没有免费版(所有功能都在付费计划后),$20/月的月付价格高于Citely的$19/月,但年付价格更贵(约$144/年 vs Citely年付$168/年,差距不大但Scite提供功能深度更高);在学术文献覆盖上有一定学科偏向(自然科学和医学领域覆盖更全面,部分人文社科领域覆盖有限);对于刚开始接触学术写作的用户,Scite的引用分类概念和界面有较高的学习成本。
与Citely的本质差异:
Scite和Citely的核心服务对象是同一类用户(严肃研究者),但解决的是引用工作流的不同阶段问题。Citely解决的是”提交前核查:这个引用是否真实存在?”;Scite解决的是”研究过程中:这个研究声称有多强的证据支撑?学术界对它的真实看法是什么?”。两者是互补而非替代的关系。
竞品二:Zotero(含ZoteroGPT功能)
定位: 全球最广泛使用的开源免费参考文献管理工具,历史超过15年,拥有庞大的学术社区生态,近年来通过插件生态(特别是ZoteroGPT等AI插件)逐步集成AI能力,在引用管理功能维度与Citely存在部分重叠,但定位、商业模式和功能深度有根本差异。
核心功能: 浏览器一键捕获文献信息(书签栏插件)、PDF注释与全文阅读、文献库组织与分类、Word/LibreOffice引用插件(写作中直接插入引用)、文献格式化(Citation Style Language支持6,000+引用格式)、开放API(第三方集成)、云同步(300MB免费,1GB+需付费)、小组库功能(多人协作文献管理)。完全免费(云存储空间付费扩容)。
优势深析:
Zotero的最大优势是完全免费+成熟生态——核心功能100%免费,所有主流功能无需付费,且经过15年打磨,在稳定性和功能完整性上达到了极高水准;引用格式支持超过6,000种(Citely只支持5-6种主流格式)是同类工具绝对的格式覆盖冠军;与Word、LibreOffice、Google Docs的写作流程集成是无缝的,在写作过程中直接插入引用、自动更新参考文献列表的功能是Citely没有的核心写作辅助能力;开放API和活跃的第三方插件生态(ZoteroGPT、PDF翻译插件、知识图谱插件等)使Zotero的能力边界远超其核心功能。
劣势深析:
Zotero完全没有Citely的假引用检测能力——它管理你告诉它要管理的引用,但不主动验证这些引用是否真实存在或元数据是否正确;AI辅助功能依赖第三方插件(如ZoteroGPT),集成度和稳定性不如原生AI功能;Source Finder(学术搜索发现)功能需要依赖外部数据库的浏览器捕获,没有Citely的语义搜索能力;对引用幻觉问题完全没有系统性解决方案。
与Citely的本质差异:
Zotero和Citely服务于引用工作流的不同环节,且在核心能力上几乎没有真正的功能重叠——Zotero是”引用管理平台”(组织、格式化、在写作中使用),Citely是”引用验证工具”(确认引用的真实性)。最理想的组合是在Zotero中管理文献库,在提交前用Citely进行验证,两者在工作流上是串联而非竞争关系。
竞品三:Consensus
定位: AI驱动的学术搜索引擎,以”用自然语言研究问题直接获取有文献支撑的答案”为核心价值,通过语义搜索1.2亿+学术论文为用户提供基于真实研究证据的问答服务,与Citely在”找到真实可信的学术来源”这个目标上有功能交集。
核心功能: 自然语言学术问题搜索(用问题句子而非关键词搜索)、Consensus Meter(显示学术界对某个研究问题的整体共识度)、Paper Search(基于问题的语义论文搜索)、Study Snapshots(AI生成的研究结果摘要)、Copilot(AI写作助手,将发现整合进写作)。定价:免费版(有限功能),Pro版约$19/月(年付约$11.99/月)。
优势深析:
Consensus在”学术证据搜索”上的质量是同类工具中最高的之一——Consensus Meter功能提供了对一个研究问题的学术共识度的量化可视化,帮助用户快速理解”学术界整体上是否支持这个结论”,这对于研究者评估一个论点的证据强度有独特价值;自然语言问题搜索的用户体验极为流畅,普通人不需要学习布尔检索语法即可获得高质量搜索结果;年付$11.99/月的价格在同类学术AI工具中是最有竞争力的。
劣势深析:
Consensus完全没有Citely的假引用检测功能——它帮你找到真实文献,但不帮你验证你已有的引用是否真实;引用格式化功能基础,不能替代Citely的专业格式管理;文献覆盖主要针对开放获取(Open Access)和已被Semantic Scholar索引的文献,在付费数据库独家文献的覆盖上有缺口;对于引用幻觉问题,Consensus的应对策略是”提供真实来源”而不是”核查已有引用”,两者在问题解决的方向上是互补而非替代的。
与Citely的本质差异:
Consensus是”向前看的来源发现工具”(找到支持你论点的真实研究),Citely是”向后看的引用核查工具”(验证你已经引用的内容是否真实)。两者在引用工作流的不同节点各有价值,最佳实践是用Consensus发现和选取来源,用Citely在提交前核查参考文献的完整性。
竞品四:SciSpace(原Typeset.io)
定位: 综合性学术研究平台,以”AI驱动的论文阅读理解和文献发现”为核心,拥有超过2.2亿篇学术论文的全文数据库,提供从文献搜索、PDF全文阅读(带AI解释)到写作辅助的完整研究工作流支持,是学术AI工具市场中功能覆盖最广的平台之一。
核心功能: AI PDF阅读器(PDF内直接提问,AI基于论文全文回答)、文献语义搜索(类似Consensus但数据库更大)、AI写作助手(论文草稿生成辅助)、引用管理(基础功能)、实验数据提取(从论文中提取表格和数据)、研究话题跟踪。定价:免费版(有限功能),Pro版约$20/月(年付约$12/月)。
优势深析:
SciSpace的核心竞争力在PDF全文阅读理解——用户上传一篇学术PDF后,可以直接向AI提问关于这篇文章的任何问题(”这篇文章的研究限制是什么?”、”作者用了什么统计方法?”),AI基于全文内容精确回答,这个功能在快速理解和评估文献的效率上远超其他工具;2.2亿+文献的全文数据库是业内最大的商业学术AI数据库之一;文献发现、PDF阅读、写作辅助三个核心功能整合在一个界面,用户体验流畅连贯;年付$12/月的价格在同等功能覆盖的工具中非常有竞争力。
劣势深析:
SciSpace没有Citely的假引用检测核心能力——在”验证已有引用的真实性”这个功能维度,SciSpace基本是空白;引用格式化功能相对基础;批量引用验证和报告生成不在其功能矩阵中;对于专门需要提交前引用质量保障的场景,SciSpace的功能组合与这个需求的匹配度较低。
与Citely的本质差异:
SciSpace是”大而全的研究工作流平台”,在文献阅读理解和内容发现上功能深度很高;Citely是”专注于引用真实性的单点工具”,在假引用检测这个核心功能上没有竞品能够替代。两者在功能覆盖上几乎没有真正的重叠——使用场景是串联的,而非竞争的。
竞品五:Turnitin iThenticate(Academic Integrity检测系统)
定位: 全球学术机构最广泛使用的学术诚信检测系统,原以”抄袭检测”(查重)起家,近年来加入了”AI检测”功能,在引用合规检测的某些维度与Citely存在功能交集,但两者的核心机制和目标用户层次有根本区别。
核心功能: 全文相似度检测(与庞大的学术文献和网络内容数据库进行相似性比对)、AI写作检测(检测文本中的AI生成内容比例)、引用验证(基础级别的引用格式检查)、机构级别的提交管理系统、学生提交的历史记录和追踪。定价:机构级许可证(按学校或机构整体购买,不向个人用户直接销售),个人研究人员版(iThenticate)约$100-$200/年。
优势深析:
Turnitin的最大优势是机构权威性和学术认可度——全球超过1万所大学和学术机构使用Turnitin,其查重报告在学术诚信审查中具有法律和制度层面的认可度;专有的文献数据库(包括大量已发表期刊文章的全文内容)在某些文献类型的相似性检测上是其他工具无法匹配的;AI检测功能在2023-2025年快速成熟,覆盖GPT-4、Claude等主流模型的检测。
劣势深析:
Turnitin完全没有Citely专注的”假引用检测”——Turnitin检测的是相似性(抄袭),不检测引用的真实性(幻觉);对个人用户的直接访问门槛很高(价格昂贵,主要通过机构账号使用);AI检测功能的误报率和不稳定性问题一直是被诟病的点(包括Curtin University等高校已经基于此决定停用AI检测功能);产品界面和使用体验相比现代SaaS工具显得陈旧,没有Citely那样的直观引导式工作流。
与Citely的本质差异:
Turnitin是”基于相似性的内容合规检测系统”,面向机构合规管理;Citely是”基于真实性的引用验证工具”,面向研究者个人质量保障。两者检测的是完全不同维度的学术质量问题:Turnitin回答”这段内容是否抄袭自其他来源?”;Citely回答”这个引用指向的文献是否真实存在?”。这两个问题在逻辑上是独立的,都需要被回答,但需要不同的工具来解决。
五款工具核心参数横向对比
六、谁最适合使用Citely?
在学术投稿前进行参考文献合规检查的研究人员:论文被期刊退稿的原因之一,正在越来越多地涉及引用质量问题——编辑收到的AI辅助撰写稿件中,虚假引用的频率显著上升,部分期刊已经开始对参考文献进行批量核查。对于有正式发表需求的研究人员,在投稿前用Citely进行一次全面的引用验证,是一个性价比极高的学术风险管控措施(每次核查消耗2-4个credits,成本不足$1)。
大量使用AI工具辅助写作草稿的学术写作者:如果工作流程包括用ChatGPT、Claude或Gemini生成文献综述草稿或论文段落,Citely解决的是这个工作流中最危险的质量风险点。AI生成内容本身的引用幻觉问题无法通过人工阅读可靠地识别,Citely的自动化批量验证是目前最有效率的解决方案。
PhD学生和硕士生(毕业论文提交前的最终核查):毕业论文的参考文献列表通常包含60-150条引用,手动逐条核查是一项时间成本极高的工作。Citely可以在几分钟内完成整份参考文献列表的批量验证,帮助学生在提交答辩版本前确认引用质量,避免因引用错误导致的答辩质疑或后续修改要求。
学术期刊编辑和同行评审委员:在审稿流程中快速识别引用质量有问题的投稿,是Citely在机构层面的核心商业场景。对于处理大量AI辅助稿件的期刊(在2025-2026年这已经是所有活跃期刊的现实),Citely的批量核查能力在提升审稿效率和维护期刊声誉上有直接的工具价值。
跨学科研究者(引用不熟悉领域的文献时):当研究需要引用自己专业以外领域的文献时,研究者通常没有足够的专业知识来判断一个引用是否看起来可信。AI生成的幻觉引用在用户不熟悉的领域更难被人工识别,Citely的数据库交叉验证在这个场景下的价值最高。
七、已知局限与客观使用边界
对中文及非英语文献的覆盖缺口:Citely的五大数据库(CrossRef、PubMed、arXiv、OpenAlex、Google Scholar)在英语学术文献上的覆盖是全面的,但对中文、日语、德语等非英语学术文献的覆盖有明显不足。测试显示,CNKI(中国知网)和万方数据库中的中文文献,即使拥有DOI,在Citely中的验证成功率显著低于英语文献。这意味着在中文文献比例较高的论文中(如中国研究、中文期刊投稿、中文文学研究),Citely的引用验证结果不能全面代表论文引用质量的整体状况。
最新文献的数据库同步延迟:在测试中发现,2025年下半年以后发表的最新文章在Citely中有时无法完成验证(返回”需要人工确认”而非”验证通过”)。这是任何依赖外部数据库的引用验证工具的共同限制——学术数据库的记录更新通常落后于实际发表时间1-6个月,最新发表的文献在这个时间窗口内无法完成自动化验证,需要人工手动确认。这个限制在引用大量最新文献的前沿研究领域(如AI、基因技术)更为明显。
语义引用准确性的局限(”引用目的”验证):Citely能高精度验证一个引用”是否存在”,但对于更深层次的”这个引用是否被正确使用了”(即被引文献的实际结论是否真的支持引用它的论述),Citely的语义验证能力仍然有限。专业术语领域的微妙引用错误(如引用一篇文章的某个次要发现来支持一个主要论断)不在Citely的核心检测能力范围内,仍然需要领域专家的人工判断。这个局限意味着Citely通过验证的引用不等于”引用使用正确”,只等于”引用的文献真实存在且元数据基本准确”。
没有写作流程嵌入(非实时辅助工具):Citely是一个”提交前检查”工具,而不是”写作过程中”的实时辅助工具——它没有Word插件、没有Google Docs集成、没有Chrome扩展,无法在用户写作的过程中实时提示引用风险。用户需要在写作完成后将参考文献列表手动提交到Citely界面进行核查,这个工作流形式适合作为提交前的最终QC环节,但无法替代写作过程中与参考文献管理工具(如Zotero)的实时集成体验。
Credits计费模式在长文档处理上的不透明性:虽然Credits计费规则(每2,000字符1个credit)是公开的,但对于初次使用的用户,在提交大型文档前预估costs的认知成本偏高——不同长度的文档消耗不同数量的credits,且credits是在结果交付后扣费,这意味着用户在操作前无法确定本次核查的确切成本,存在轻微的支出不可预测性。这个设计与”先扣后用”的预付费模式相比,透明度稍低。





