










Dimensions AI
Dimensions AI,全球最大的关联研究数据库提供智能分析解决方案连接研究生态系统实现快速洞察
标签:文献检索 科研实用工具Dimensions AI Dimensions AI官网 Dimensions AI官网入口Dimensions AI官网:面向全球学术与科研生态的智能研究数据平台
什么是Dimensions AI?
Dimensions AI(dimensions.ai)是一款以人工智能为核心驱动力的综合性学术研究数据平台,由 Digital Science 公司开发运营,面向全球科研社区提供从文献检索、数据分析到战略洞察的全链路研究支持服务。平台汇聚了迄今为止全球最大规模的互联研究数据集合,覆盖超过 3.5 亿条跨学科数据记录,数据类型多元,包括期刊论文、会议摘要、科研基金、专利、临床试验、研究数据集及政策文件等,是全球学术情报领域的重要基础设施。
Dimensions AI官网: https://www.dimensions.ai/
Dimensions AI深度评测:这个号称”全球最大互联研究数据库”,凭什么值得每个科研人关注?
在学术数据库的世界里,有一种产品长期活在两个巨人的影子下:Web of Science代表”权威与精选”,Scopus代表”覆盖与体量”,两者联手几乎垄断了全球高校科研管理的话语权,共同支撑着基于JIF和CiteScore的期刊评价体系。
然后,2018年1月,Digital Science悄悄发布了一个叫Dimensions的东西。
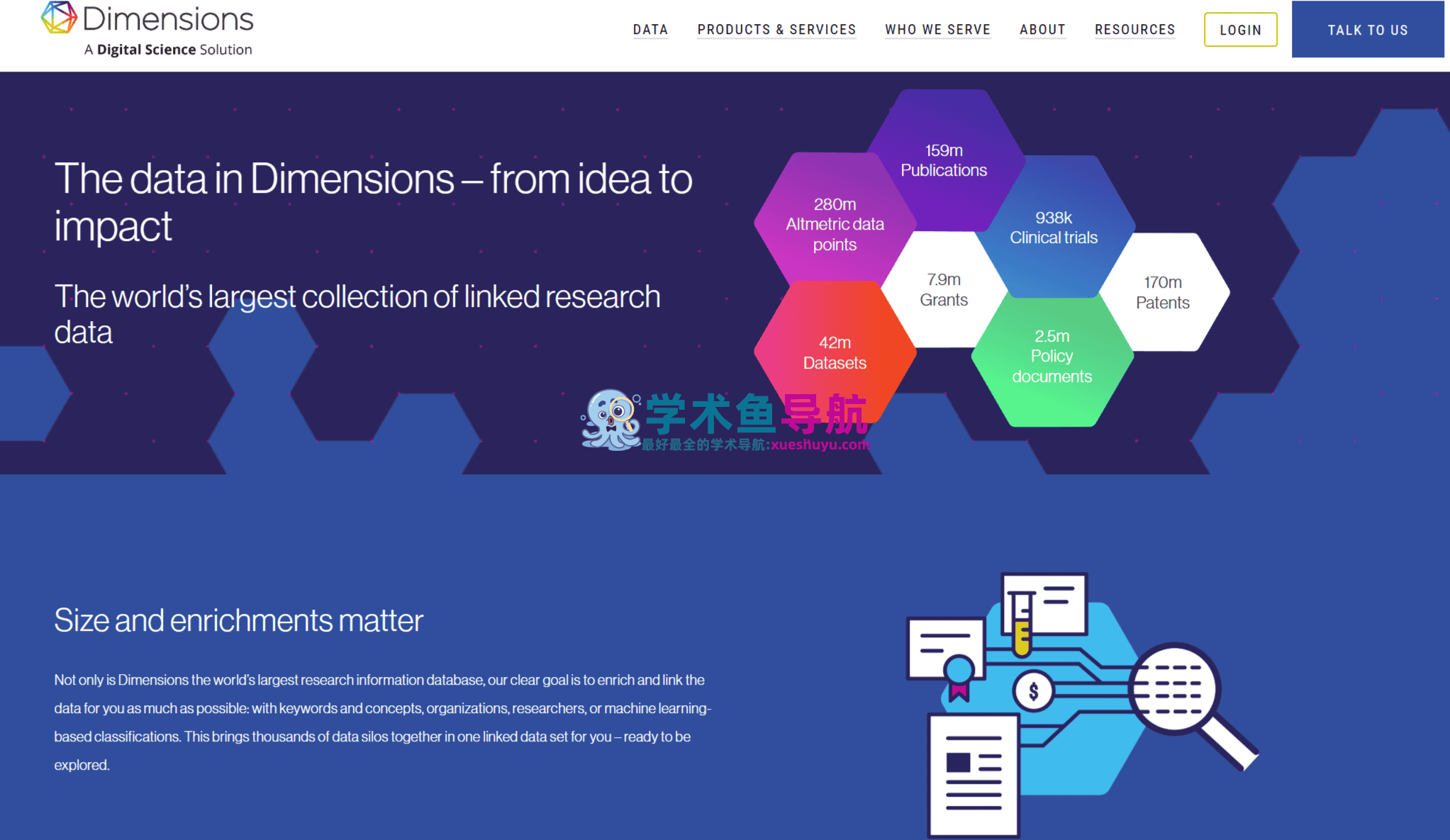
没有大张旗鼓的发布会,没有华丽的营销词汇,但这个产品从第一天起就打出了一个让业界侧目的定位:不是又一个文献检索数据库,而是一个连接研究生态全链条的知识图谱平台。文献发表只是科研生命周期的一个节点;在此之前,有科研资助(Grants);在此之后,有专利(Patents);与此并行,有临床试验(Clinical Trials);面向政策应用,有政策文件(Policy Documents);面向数据共享,有研究数据集(Datasets)。Dimensions的野心是:把这一切连接起来,让研究人员在一个界面内追踪某项发现从资助立项到知识转化的完整路径。
截至2026年4月,Dimensions已经积累了超过1.47亿篇出版物记录、1.5亿+专利记录、超过700万项科研资助记录、超过100万条临床试验记录、超过1000万项政策文件,以及覆盖70%以上出版物的全文索引——这些数字背后,是目前全球体量最大的互联研究数据集,而且其基础检索功能对所有人完全免费,无需注册。
在Web of Science被多所欧洲顶级大学以”成本效益”为由终止订阅的2025-2026年间,Dimensions的受关注程度以肉眼可见的速度上升——不仅仅是作为”WoS的廉价替代品”,而是作为一个在某些核心场景下真正比传统付费数据库更有能力的工具,获得了越来越多的专业评价。
Digital Science与Dimensions的战略背景
要理解Dimensions是什么,先要理解它的开发方Digital Science是谁。
Digital Science是英国的一家科技公司,专注于学术研究基础设施工具的开发和投资,旗下产品组合包括:文献管理工具Readcube Papers(原Papers)、学术影响力追踪工具Altmetric、数据引用平台figshare、科研评估工具Symplectic、期刊出版工具Morressier,以及Dimensions本身。Digital Science的大股东是Holtzbrinck Publishing Group,同样是施普林格·自然(Springer Nature)集团的重要股东——这个产权结构意味着Digital Science与欧洲最重要的学术出版生态之间有深度连接,但又保持了在内容遴选和产品策略上的独立性。
Dimensions的产品逻辑是Digital Science整个工具矩阵的基础设施底层:Altmetric的社交媒体学术影响力数据整合进Dimensions;ReadCube Papers的文献管理功能与Dimensions的检索发现无缝对接;figshare的研究数据集引用整合进Dimensions的数据集检索;这种生态协同使Dimensions的功能延伸边界远超一个单纯的文献数据库。

数据库规模与内容结构

出版物(Publications):1.47亿+条记录
Dimensions的文献覆盖包含以下几个主要组成部分:
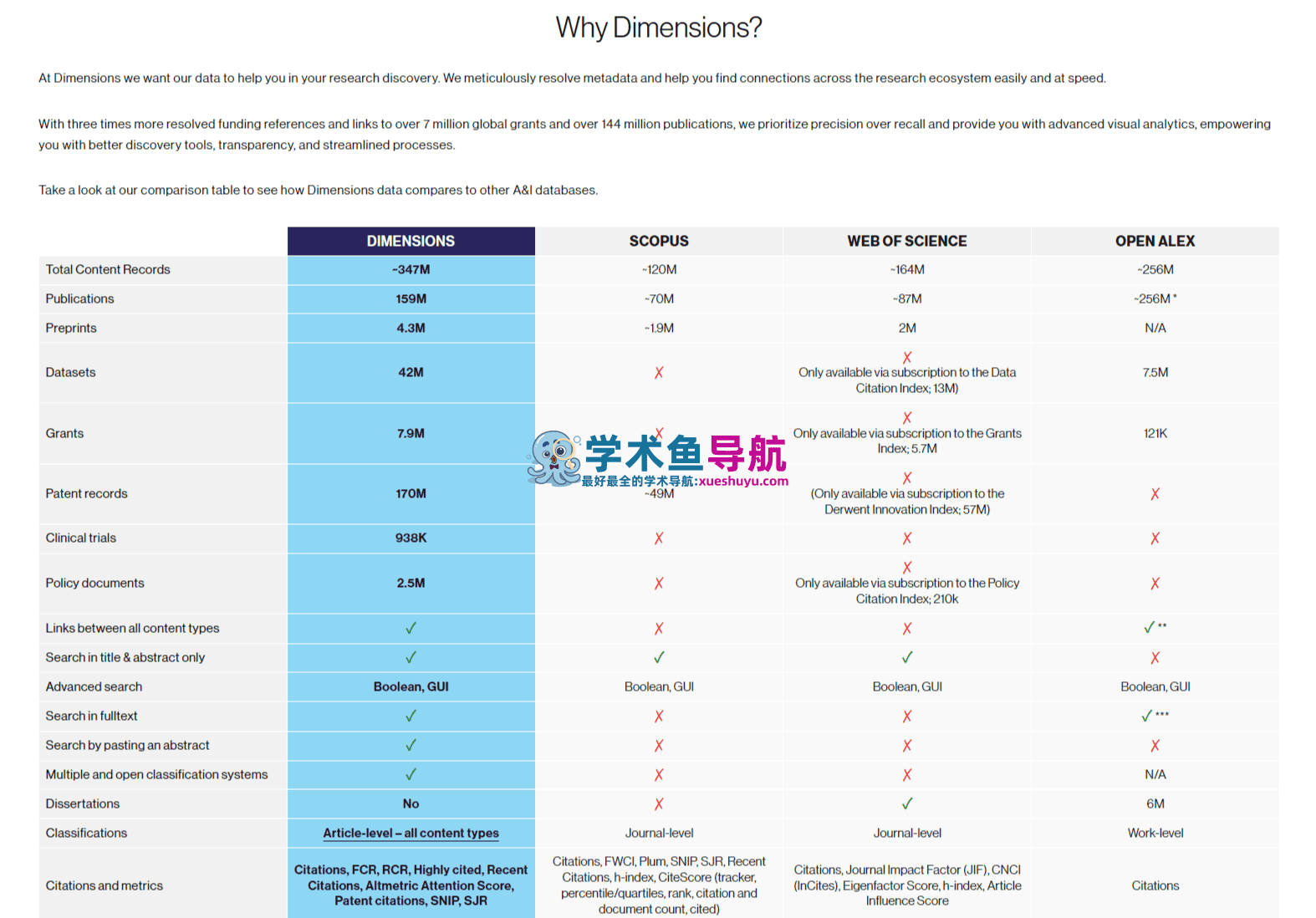
同行评审期刊文章:收录来自全球77,471+种期刊的文章(这个数字约是Scopus的2.8倍、Web of Science Core Collection的约3.4倍),涵盖自然科学、工程、医学、社会科学、艺术与人文全部学科领域。期刊覆盖的宽泛性是Dimensions最核心的量化优势,特别是对非英语语言学术出版物、发展中国家区域性期刊、新兴开放获取期刊的收录密度,远超两大传统竞品。
全文索引覆盖率:Dimensions对超过70%的文献记录提供全文索引(而不仅是摘要索引),这意味着检索可以穿透到文章正文内容,不只是依赖标题、摘要和关键词——这对于那些核心概念出现在正文方法部分或结果讨论中、而不在摘要里的检索场景,提供了Web of Science和Scopus无法实现的查全率。
时间覆盖:文献记录最早可追溯至1665年(与人类第一本专业科学期刊《Philosophical Transactions of the Royal Society》的创刊时间几乎同步),引用数据从1665年持续至今,历史覆盖深度在主流商业数据库中是最长的(Scopus的完整引用数据从1970年开始,Web of Science标准覆盖从1945年开始)。
预印本整合:Dimensions覆盖arXiv、bioRxiv、medRxiv、SSRN、ChemRxiv等主要预印本平台的文献,并在预印本发表为正式期刊文章时进行版本关联,避免同一研究以预印本和最终版本两次出现在引用统计中造成混乱。
科研资助(Grants):700万+条记录
这是Dimensions最独特的内容模块,也是区别于所有其他主流学术数据库的核心差异化资产。
Dimensions收录了来自全球主要资助机构的科研资助授权记录,包括美国NIH(国立卫生研究院)、NSF(国家科学基金会)、英国UKRI(英国研究与创新机构)、欧盟Horizon项目、德国DFG(德国研究联合会)、澳大利亚ARC(澳大利亚研究委员会)等全球重要资助机构的授权记录,以及中国自然科学基金委(NSFC)等亚洲资助机构的部分记录。
资助→出版物的双向连接:每条资助记录与其资助产出的出版物之间存在双向链接——从资助记录出发,可以直接查看该项目产出了哪些论文;从任意论文出发,可以追溯这篇论文由哪些资助项目支持。这种连接使科研资助机构可以精确追踪每一笔经费的知识产出,也使研究人员可以找到特定研究方向的历史资助模式作为基金申请的参考背景。
专利(Patents):1.5亿+条记录
Dimensions整合了来自美国USPTO、欧洲EPO、世界知识产权组织WIPO、中国CNIPA等全球主要专利机构的1.5亿+专利记录,并建立了专利文献与学术出版物之间的引用关联——即某项专利引用了哪些学术文献(基础科学→应用技术的知识转化路径),以及某篇学术文献被哪些专利引用(学术研究对工业应用的影响力证明)。
这种学术-专利引用网络对于以下具体场景有不可替代的价值:技术转移办公室评估某项大学科研成果的知识产权潜力;政策研究人员分析特定领域的科学-技术转化效率;科研人员评估自己所在研究方向的工业应用前景。
临床试验(Clinical Trials):100万+条记录
覆盖ClinicalTrials.gov(美国)、EU Clinical Trials Register(欧盟)、ISRCTN(英国)等主要临床试验注册平台的记录,与相关学术文献、资助数据建立关联。对于医学、公共卫生、药学研究人员,Dimensions提供了从基础研究文献→临床试验注册→临床研究发表的完整知识转化追踪能力,这是其他数据库没有系统性提供的功能。
政策文件(Policy Documents):1000万+条记录
覆盖各国政府政策报告、智库报告、国际组织文件中对学术研究的引用,追踪科学研究对政策制定的实际影响路径——即”某篇科学文章,最终影响了哪些国家的哪些政策文件”。对于关注科学-政策接口的研究人员(公共卫生政策、气候变化政策、科技创新政策等方向),这是目前在其他数据库中完全找不到的功能模块。
研究数据集(Datasets):2900万+条记录
整合Figshare、Zenodo、Dryad等主要研究数据存储平台的数据集记录,使研究数据成为Dimensions知识图谱中可检索、可引用的独立单元,支持研究人员发现某个研究方向已经公开的数据资源,而不需要逐一访问各数据存储平台。
核心功能深度解析
一、统一检索界面:跨内容类型的全域检索
Dimensions的检索界面设计体现了一个核心理念:研究人员不应该在文献库、专利库、资助库之间切换界面进行重复检索,应该在一个统一的检索框内,对所有类型的研究数据进行整合检索。
基础检索(免费用户可用)
主搜索框支持对出版物进行自然语言全文检索,对于免费版用户,可检索的内容类型包括出版物(Publications)和数据集(Datasets)。付费版(Dimensions Plus)扩展检索范围至资助、专利、临床试验和政策文件。
检索过滤器(免费版可用的部分):
-
来源标题(Source Title):限定在特定期刊内检索
-
研究人员(Researchers):通过Dimensions研究人员ID精确定位特定学者
-
机构(Organizations):限定在特定机构发表的文献
-
开放获取状态:只显示有合法免费全文版本的文献(细分为Gold OA、Green OA、Bronze OA等类型)
-
年份范围:自定义时间区间
-
文献类型:期刊文章、综述、会议论文、书籍章节等
-
学科领域:基于FOR(澳大利亚研究领域)分类体系的学科筛选,覆盖22个一级学科大类
全文检索的实质优势
Dimensions对70%以上文献记录提供的全文索引,使得”检索词只出现在文章正文中、不出现在标题摘要关键词里”的文献也能被找到。这种”穿透摘要”的检索能力,在以下场景有具体价值:新兴技术名词的早期出现(在技术命名标准化之前,文章可能只在正文中使用了这个词,还没有用它做关键词);方法论描述(某种具体统计方法或实验技术的描述往往只出现在方法部分);特定研究场景的描述性检索(检索词描述的是研究对象的具体状态,而不是研究主题)。
二、AI功能体系:2025年的三大核心更新
2025年是Dimensions在AI功能方向迈出最重要步伐的一年,三个核心更新重塑了平台的智能辅助能力。
① AI Summarization(AI摘要):即时研究概览
AI Summarization功能将自然语言处理应用于检索结果集合,对任意检索主题自动生成一份综合性的研究概述,包括:该领域的主要研究方向、近年重要发现的关键词级摘要、主要活跃机构和研究人员、研究成果的时间趋势描述。这个功能对于快速建立陌生研究领域的初步认知特别有效——不需要逐篇阅读摘要,通过AI摘要可以在几分钟内了解一个研究方向的整体格局。
AI Summarization在免费版中对大多数用户可用,是Dimensions将AI能力向免费用户开放的标志性举措。
② Topic Refine(主题精炼):2025年7月发布的AI聚类功能
Topic Refine是2025年中期最重要的产品更新,核心是将AI聚类分析应用于检索结果集合——把大量文献按主题自动分组,形成有层次结构的主题簇(Cluster)和子主题簇(Sub-cluster)。
面对一个包含数千篇文献的检索结果,研究人员面临的真实挑战是:知道哪些文献存在,但不知道它们之间的主题关系,不知道这个领域内部有几个方向,每个方向的代表性文献是哪些。Topic Refine直接解决这个问题:
-
自动主题聚类:AI分析检索结果集合中所有文献的全文(而不只是摘要关键词),识别语义相似度高的文献组合,形成有意义的主题分组
-
自动标签生成:每个主题簇自动获得一个语言描述性标签,说明这个簇内文献的共同主题
-
层次结构:支持主题簇→子主题簇的层次化展示,对于大型检索结果集合可以形成二级甚至三级的主题树
-
簇内导出:用户可以选择一个或多个感兴趣的主题簇,将其导出为独立的文献集合,继续在Dimensions中做深入检索或直接导出数据
Topic Refine目前对Academic、Publisher、Enterprise订阅用户开放,免费版用户暂时不可用。从目前的用户反馈来看,Topic Refine对于以下两个具体场景效率提升最明显:系统综述的文献分类(将大量初检文献按主题初步分组,为后续人工精筛提供有结构的起点);研究方向探索(第一次进入一个陌生学科方向时,了解该方向内部的子方向分布格局)。
③ Dimensions Research GPT:ChatGPT生态整合
Dimensions与OpenAI合作,在ChatGPT Plus和Enterprise的插件生态中推出了Dimensions Research GPT,使ChatGPT用户可以直接在ChatGPT界面内向Dimensions的开放获取文献数据库提问,并获得带有文献来源引用的回答,点击引用可以跳转到Dimensions文章详情页。
这个整合的意义在于:弥补了通用AI工具(如ChatGPT)在学术文献幻觉引用方面的已知缺陷——通过Dimensions Research GPT,ChatGPT的回答可以”锚定”在Dimensions开放获取文献库的真实文献上,而不是AI自行生成的虚假引用。对于在ChatGPT工作流中需要可靠文献支持的研究人员,这提供了一个比纯依赖ChatGPT记忆的学术问答更可信的方案。
三、Research Security(研究安全):2025年9月发布的新产品线
2025年9月30日,Digital Science正式发布了Dimensions Research Security API——这是Dimensions产品线向一个全新应用场景的重要扩展:研究安全(Research Security)合规管理。
背景:2024-2025年间,随着美国《研究安全和信息保护》政策、英国《高等教育(自由表达)法案》的相关研究安全条款、欧盟战略自主政策对外国研究合作的审查趋严,全球大学和研究机构面临日益增加的监管压力:需要对参与外部合作(特别是涉及某些国家机构的合作)的研究人员进行合规审查,识别潜在的利益冲突、未申报的双重机构关联或来自受限资金来源的资助接受情况。
Dimensions Research Security的工作逻辑:
利用Dimensions数据库中的研究人员档案(关联机构历史、合著关系网络、资助接受记录)和全球研究合作关系数据,对机构提交的研究人员名单或合作项目进行自动风险扫描:
-
双重机构关联识别:某研究人员是否同时附属于本机构和另一个(需要特别关注的)外部机构,且未在公开文件中明确披露
-
敏感资助来源追踪:研究项目的资金是否来自需要特别关注的资助机构或国家
-
合作网络异常:研究人员的合作关系网络中是否包含需要进一步审查的实体
-
API直接集成:通过系统级API接口,将上述风险扫描功能直接嵌入机构的HR系统、合规管理系统或科研项目申报系统中,使合规审查成为常规工作流程的一部分,而不是需要单独操作的附加步骤
这个产品面向的核心客户群是高等教育机构的科研合规部门、政府科研资助机构的审查部门、以及国防相关研究机构的安全合规团队——一个在2025年以前完全没有任何主流学术数据库提供系统化支持的细分需求领域。
四、可视化分析工具
Analytical Views(分析视图)
对任意检索结果集合,Dimensions提供以下维度的统计可视化:
-
发文量时间趋势:折线图显示该方向近年发文量变化,快速判断研究方向的活跃度走向
-
开放获取比例趋势:显示该方向的开放获取发表比例变化,了解所在学科OA化进程
-
Altmetric Attention Score分布:显示该检索结果集合中高Altmetric得分文章的比例,判断该方向研究的社会关注度
-
机构发文量分布:全球发文量前25名机构排行,识别该方向的核心研究机构
-
资助机构分布:支持该方向研究的主要资助来源分布,帮助判断哪些资助机构对这个研究方向有资助意愿
-
地理分布热力图:全球各国/地区的发文量分布,识别研究重心
-
合作关系图:机构间共著合作网络可视化
Horizon Scanning(地平线扫描)
这是Dimensions为机构和政策用户设计的战略分析功能,核心是对”某个技术或研究方向在最近几年的研究活动模式变化”进行系统性分析:发文量是否加速增长(研究活跃度上升信号)、资助量是否同步增加(有外部资金支持)、是否有从纯学术发表向专利产出的转化趋势(技术成熟度提升信号)、主要资助机构是否从学术性转向产业性(应用化进程信号)。Horizon Scanning将这些多维度信号整合在一个可视化仪表盘中,支持研究机构、资助机构、政府政策部门对技术趋势做出系统性判断。
五、Researcher Profiles(研究人员档案)
Dimensions维护了一套基于机器学习算法的研究人员消歧义(Author Disambiguation)系统,将不同文章中的同名/相似名称作者识别并归并到统一档案,同时支持与ORCID、ResearcherID等标准学者识别系统的关联。
每个Researcher Profile显示:所有发表文献列表(含被引次数、Altmetric分数、OA状态标识)、h指数、发文年份分布、主要合作者网络、主要研究领域、所属机构历史、资助记录(如果该研究人员是资助申请主体),以及获批专利记录(如果存在)。
这种”全生命周期研究人员画像”比Web of Science ResearcherID档案(以引文数据为主)或Scopus Author Profile(以引文数据和机构关联为主)视角更宽,整合了资助和专利这两个传统引文数据库档案中完全缺席的维度。
六、API与数据开放
Dimensions的API体系是其相对传统数据库最重要的生态开放策略:
Dimensions API(DSL查询语言):支持通过类SQL语法(Dimensions Search Language,DSL)对数据库进行程序化查询,允许研究人员构建自定义的文献计量分析、知识图谱构建、趋势分析脚本。对学术用户,Dimensions的基础API访问是免费的(有速率限制),这在商业学术数据库中极为罕见——Scopus和Web of Science的API访问均需要机构订阅。
Dimensions API Excel Add-In(2026年3月正式版本更新):Dimensions的Excel插件允许研究人员和机构分析师在Excel界面内直接执行DSL查询,将结果转化为Excel可处理的表格格式,无需编程能力即可利用API的批量数据能力——2026年3月的更新版本提升了查询执行稳定性和大数据集处理能力。
Dimensions Research Security API(2025年9月):如前所述,面向机构合规系统的专项API集成接口。
免费版与付费版(Dimensions Plus)的功能边界
Dimensions的定价模式是”慷慨的免费版+机构付费版”二元结构,这是它与Web of Science和Scopus最大的商业模式差异。
免费版(无需注册即可使用,注册后功能更完整):
Dimensions Plus(机构订阅版):
定价采用谈判制,根据机构类型和规模定价。根据公开资料,机构年度订阅起步价格在**$10,000-$30,000**区间,大型研究型大学的费用可能更高,但普遍低于同等规模机构的Web of Science订阅价格,这使Dimensions Plus在成本效益上对许多机构更具吸引力——特别是对那些已经在使用Web of Science但考虑成本的机构,以及那些希望将研究安全、资助追踪、专利监控整合进研究管理工作流的机构。
Dimensions API学术免费访问:独立研究人员和学术用户可以申请免费的API访问资格,速率限制为每月30,000次查询(对于个人研究项目已经相当充裕),对于大规模文献计量研究有明显的成本优势。
实测评价:Dimensions AI的真实使用体验
真实好用且难以复制的场景:
资助→文献→专利全链条追踪是Dimensions最独一无二的核心能力,在其他任何学术数据库中都找不到同等深度的实现。当一位科研政策研究员需要回答”某国政府2015-2020年在人工智能医疗应用方向的资助投入,最终产出了多少学术成果,其中有多少转化为了专利”时,在其他数据库中需要跨越多个系统进行人工交叉比对才能回答的问题,在Dimensions中可以通过一次会话完成。这种全链条数据密度,目前是Dimensions无可替代的资产。
全文检索的查全率优势在交叉学科研究、新兴技术方向检索中有可量化的实际效果。对于研究中使用的新术语或特定技术名称——当这个术语还没有成为标准关键词的时候,只在文章正文中出现——Dimensions的全文索引可以找到它,而Web of Science和Scopus的摘要级索引会漏掉。
API的免费学术访问对于计量学研究人员和需要大规模数据分析的研究者,是极具吸引力的差异化优势。需要下载数万条文献记录做文献计量分析的研究,通过Dimensions API可以在不支付额外费用的情况下完成,而在Web of Science或Scopus上需要额外申请或付费。
开放获取文献的识别和直接访问非常便捷。在检索结果中,所有有合法免费全文版本的文献都标注了明确的OA类型,一键可以访问开放获取版本,在2025-2026年开放获取覆盖率快速上升的背景下,这个功能的实用价值持续提升。
需要正视的问题:
没有官方JIF/JCR数据是Dimensions在中国学术考核语境下的根本局限,与Scopus的情况相同。Dimensions不提供任何形式的官方期刊影响因子数据,在中国高校职称评定、科研绩效考核等场景中,这使Dimensions无法单独作为期刊质量评估的工具。
引文数据的质量控制不如Web of Science和Scopus严格。Dimensions的覆盖量优势是建立在相对宽松的内容收录标准上的——收录门槛更低意味着覆盖更广,但同时也意味着来源质量更参差不齐。当需要高质量文献计量分析(如科学产出的学科对比研究)时,Dimensions的引用数据中包含的低质量文献会比Web of Science多,需要更谨慎的后处理。
免费版的核心差异化功能(资助、专利、临床试验)不可用,使免费版Dimensions对于需要全链条分析的用户来说只是一个覆盖量更大的文献搜索引擎,而不是真正体现其产品独特性的工具。对于只做文献检索而不需要资助和专利数据的用户,免费版Dimensions与免费版Google Scholar的实际差距,可能没有宣传的那么大。
Topic Refine和Horizon Scanning等AI功能对免费用户完全关闭,这与Dimensions一贯的”慷慨免费”形象形成了一定落差——在AI功能的开放性上,Dimensions做得不如其在基础检索功能上的免费策略那么彻底。
5款同类产品横向精讲
1. Web of Science
Web of Science是Dimensions最有意识地对标的竞争对手,Digital Science甚至在官网上发布了独立学者对两者的比较研究,宣称Dimensions在发文量覆盖上”远超Web of Science”。
核心优势(相对Dimensions): 官方JIF/JCR数据的独占权——这是Web of Science在中国学术考核体系中的结构性护城河,任何Dimensions的覆盖量优势都无法在这个维度形成替代;ESI高被引论文和高被引科学家排名,是全球认可度最高的学术影响力量化标准;引用数据从1900年起的深度历史覆盖(Century of Science模块);SCIE/SSCI/AHCI的精选标准使数据库内期刊的平均质量密度高于Dimensions;Literature Review 2.0的AI文献综述与可信引文数据整合;多所欧洲顶校作为终止WoS订阅的”理由”之一,间接证明了它的存在感,同时也证明它的价格问题已经引起广泛关注。
核心劣势(相对Dimensions): 期刊覆盖约20,000+种,远小于Dimensions的77,471种;没有资助数据库、专利数据库、临床试验记录的整合覆盖;没有全链条研究生命周期视角;没有研究安全合规功能;定价高昂且透明度更低;个人用户的免费访问几乎不存在;全文索引覆盖率不如Dimensions。
2. Scopus
Scopus是Dimensions在商业学术数据库市场中最直接的覆盖量对标竞争者,两者同属”比Web of Science覆盖更广”的阵营,但商业模式、功能侧重和生态连接完全不同。
核心优势(相对Dimensions): CiteScore官方期刊评价体系——Scopus的CiteScore作为JIF之外最被学术界认可的期刊影响力指标,在中国和全球越来越多机构的考核体系中获得接受;Author Profile的27,000+种期刊覆盖下的引文数据完整性和1970年以来的连贯性;Altmetric整合(虽然Dimensions也有,但Scopus与Altmetric的整合界面更成熟);Scopus AI Deep Research的AI文献综述能力在可信引文支持下的综合质量;SciVal的深度机构分析整合;期刊收录标准更严格,数据质量控制更可靠;在全球大学图书馆中的机构订阅基础更成熟。
核心劣势(相对Dimensions): 没有资助数据库、专利数据库、临床试验记录的整合;没有全链条知识转化追踪能力;没有研究安全合规功能;没有免费版本(对没有机构订阅的个人用户完全关闭);API访问需要机构订阅;覆盖量(1亿)略小于Dimensions(1.47亿);期刊覆盖(27,950种)远小于Dimensions(77,471种)。
3. Google Scholar
Google Scholar代表了与Dimensions完全不同的产品逻辑——极致的覆盖量和零成本可及性,不追求数据质量控制和分析工具深度。
核心优势(相对Dimensions): 完全免费,无需注册,无任何门槛;文献覆盖量约3.99亿篇,是Dimensions的近3倍,覆盖学位论文、工作论文、白皮书等Dimensions不覆盖的灰色文献;引用次数通常高于Dimensions(覆盖更多引用来源,包括灰色文献);与Google Books整合的书籍章节覆盖量庞大;Scholar个人主页完全免费;中国大陆访问相对稳定(scholar.google.cn)。
核心劣势(相对Dimensions): 没有高级检索字段系统;没有期刊质量过滤;没有任何AI文献综述功能;没有资助、专利、临床试验、政策文件数据;没有引文分析和文献计量工具;数据透明度极低;批量导出能力极差;没有研究人员档案系统;没有可视化分析工具。
4. PubMed/MEDLINE
PubMed是美国国立医学图书馆维护的免费生物医学文献专项数据库,在医学领域的权威性无可取代,是Dimensions在医学研究场景中最重要的功能性竞争者(而非整体竞争者)。
核心优势(相对Dimensions): 完全免费;MeSH医学主题词体系在生物医学文献精确语义检索方面是无可替代的行业标准,检索准确率在医学领域高于Dimensions的通用全文检索;对生物医学期刊的专项收录深度(包括护理学、口腔医学、公共卫生、医疗伦理等细分学科的专刊覆盖)高于Dimensions;临床研究文献类型的专项过滤(临床对照试验、Meta分析、系统综述等文献类型标签);与PubMed Central直接整合的开放获取全文;中国大陆完全稳定访问。
核心劣势(相对Dimensions): 范围严格限于生物医学,工程、物理、化学、经济、社会学等学科覆盖几乎为零;没有资助数据库整合(虽然文章中有资助信息字段,但不是可检索的资助库);没有专利数据;没有政策文件覆盖;没有AI文献综述功能;可视化分析工具极为有限;机构/作者引文分析工具不存在。
5. Semantic Scholar
Semantic Scholar由艾伦AI研究所(AI2)开发,是Dimensions在”AI原生”方向上最直接的功能对标竞争者,两者都以免费访问和AI辅助检索为卖点,但产品哲学和功能侧重完全不同。
核心优势(相对Dimensions): TLDR(AI一句话核心要点)功能——对每篇文章自动生成一句话核心摘要,大幅降低快速文献筛选的认知成本;引用背景分类(Citation Context)——区分引用关系的性质(方法论核心引用、背景引用、对立引用等),提供比单纯被引次数更细粒度的引用质量信息;Influential Citations(有影响力的引用)——识别并单独统计”真正重要的”引用,过滤掉在被引文章中仅被顺带一提的边缘性引用;Semantic Reader的交互式PDF阅读体验(实时联想相关文献、AI辅助内容高亮);完全免费,无需注册;API完全开放,无使用量限制;产品迭代速度快。
核心劣势(相对Dimensions): 没有资助数据库、专利数据库、临床试验、政策文件;没有任何期刊指标数据;没有机构/作者统计分析工具;没有可视化分析功能;没有AI Topic Refine类的大规模主题聚类工具;对1990年代以前历史文献的覆盖相对较弱;国内访问需要科xue+_$%上罔;中文文献支持有限。
横向对比速览
谁应该选择Dimensions AI:精确使用逻辑
Dimensions在2026年的价值主张可以用四个字描述:连接与覆盖——不只是连接文献,而是连接研究生命周期的全链条;不只是覆盖发表出版物,而是覆盖资助、专利、临床试验和政策文件。
Dimensions真正有不可替代优势的角色:
科研政策研究员和科技情报分析师,需要追踪某个技术方向从资助立项到学术发表到专利产出的全链条,Dimensions是唯一能在一个平台内系统性支持这个分析的工具。高校科研管理部门,需要评估某个学科方向的研究成熟度、资助机会、国际合作格局,Dimensions的综合分析视角远超单纯的引文数据库。没有机构订阅的个人研究人员,需要大覆盖量的免费文献检索,且愿意利用API进行自定义分析,Dimensions的免费文献检索和开放API是性价比最高的选择。处于需要研究安全合规管理的机构,2025年发布的Research Security API提供了传统数据库完全没有的专项功能支持。
Dimensions的非最优场景:
需要JIF/JCR官方数据——Web of Science是唯一选项。需要CiteScore官方数据和精密的期刊评价体系——Scopus更合适。需要AI辅助系统综述数据提取——Elicit的自动化能力更专项。需要医学文献的MeSH精确检索——PubMed的医学专项深度无可替代。需要快速判断某篇文章的核心创新点——Semantic Scholar的TLDR和引用背景分析更高效。
Dimensions最值得被重新认识的方面,是它并非简单地”想做一个更大的Web of Science”,而是在回答一个不同的问题:在传统引文数据库只关注”什么论文发表了”的地方,它在追问”科研活动的全貌是什么、资金从哪里来、知识往哪里去”。这个视角的差异,使Dimensions在2026年的学术数据库版图中,占据了一个任何其他竞品都无法简单复制的独特坐标。





