











Elicit官网:AI学术研究助手,智能文献搜索、自动摘要提取、数据提取与综合、研究问题回答,帮助研究者快速完成系统性综述。
什么是Elicit?
Elicit是一款由非营利研究机构Ought开发的AI研究助手,定位为”自动化文献综述的智能伙伴”。该平台接入Semantic Scholar学术图谱,覆盖超过1.25亿篇开放获取论文,结合自研大语言模型,实现”提问-摘要-引用-对比”的一站式文献综述流程。Elicit的核心优势在于将传统”关键词-列表”式检索升级为”自然语言-结构化答案”式探索,用户只需用日常语言输入研究问题,系统即可自动检索相关文献、提取关键信息并生成可溯源的综述报告。平台已被MIT、斯坦福、清华等高校官方推荐,已生成超800万次引用级摘要,是当代科研人员提升文献调研效率的必备利器。
Elicit官网: https://elicit.com/
以下是完整博客文章,可直接复制使用:
Elicit深度评测:AI系统综述的最强工具,2026年值得研究者认真对待
系统综述(Systematic Review)大概是学术研究中最折磨人的一项工作之一。搜索文献、筛选标题和摘要、阅读全文、提取结构化数据、核对信息、汇总证据——每一个步骤都需要高度重复、高度专注的人工操作,整个过程少则数周,多则数月,而且极容易在疲劳中引入偏差。
Elicit的出现,试图把这个过程中可以自动化的部分全部自动化。它的目标不是替代研究者的判断,而是把那些纯粹机械性的重复劳动从人的时间里剥离出去,让研究者把精力集中在只有人才能做的部分——批判性评估、理论建构、洞察提炼。
自2021年上线以来,Elicit已经服务了超过200万研究者,涵盖学术机构、医疗机构、政策研究机构以及企业研发团队。2026年4月,Elicit正式推出了系统综述(Systematic Review)专项功能的完整版本,这是产品迭代史上最重要的一次里程碑,标志着Elicit从”辅助性文献工具”向”系统综述全流程AI平台”的正式转型。
背景:它是谁做的,站在什么立场上
Elicit由Ought(奥特)公司开发,这是一家总部位于旧金山的AI安全研究公司,其核心使命是开发可以辅助复杂推理任务的AI系统,并确保这些系统的行为是透明和可核查的。这个背景很重要——它解释了为什么Elicit在AI输出的可信度和来源标注上做得比大多数同类工具严谨得多:能够核查、能够溯源、能够发现AI的错误,是这个公司骨子里的产品哲学。
底层数据库方面,Elicit接入了Semantic Scholar(艾伦AI研究所运营的开放学术数据库),覆盖超过1.38亿篇学术论文,以及54.5万条临床试验数据,涵盖生物医学、机器学习、经济学、社会科学、政策研究等主要学科领域。
定价方案:最新结构
2026年的Elicit定价体系经历了几次调整,当前最新结构如下:
Basic(基础免费版):完全免费。包含:每月2次自动研究报告(Automated Reports)、无限次1.38亿篇文献的语义搜索、无限次摘要与文档对话(每次最多4篇论文同时处理)、每月20次数据提取、2个自定义提取列(Custom Columns)、Zotero导入支持。对于偶尔有文献探索需求的学生或入门用户,免费版已经具备完整的功能体验入口。
Pro(专业版):每月49美元(年付),或月付更高。包含:每年144次系统综述或自动报告、最多5,000篇论文的系统综述工作流、研究提醒(Research Alerts)、API访问、完整的数据提取能力。针对需要定期开展正式系统综述的学术研究者和临床团队。
Scale(规模版):每月169美元(年付)。在Pro基础上增加:实时多人协作编辑、图表数据提取(Figure Extraction)、每年240次报告/系统综述额度。适合需要团队协作的大型研究项目。
Enterprise(企业版):定价面议,提供无限额度、私有数据隔离、自定义集成和专属客户支持,面向大型机构和企业研发团队。
有几个值得关注的关键定价信息:系统综述(Systematic Review)功能目前仅在Pro及以上层级可用;高准确率模式(High-accuracy mode)在部分分析中可以提升提取精度,属于付费功能;API访问同样需要Pro及以上。免费版的20次月度数据提取上限,在实际深度文献综述场景下通常1-2周内就会耗尽。
核心功能深度解析

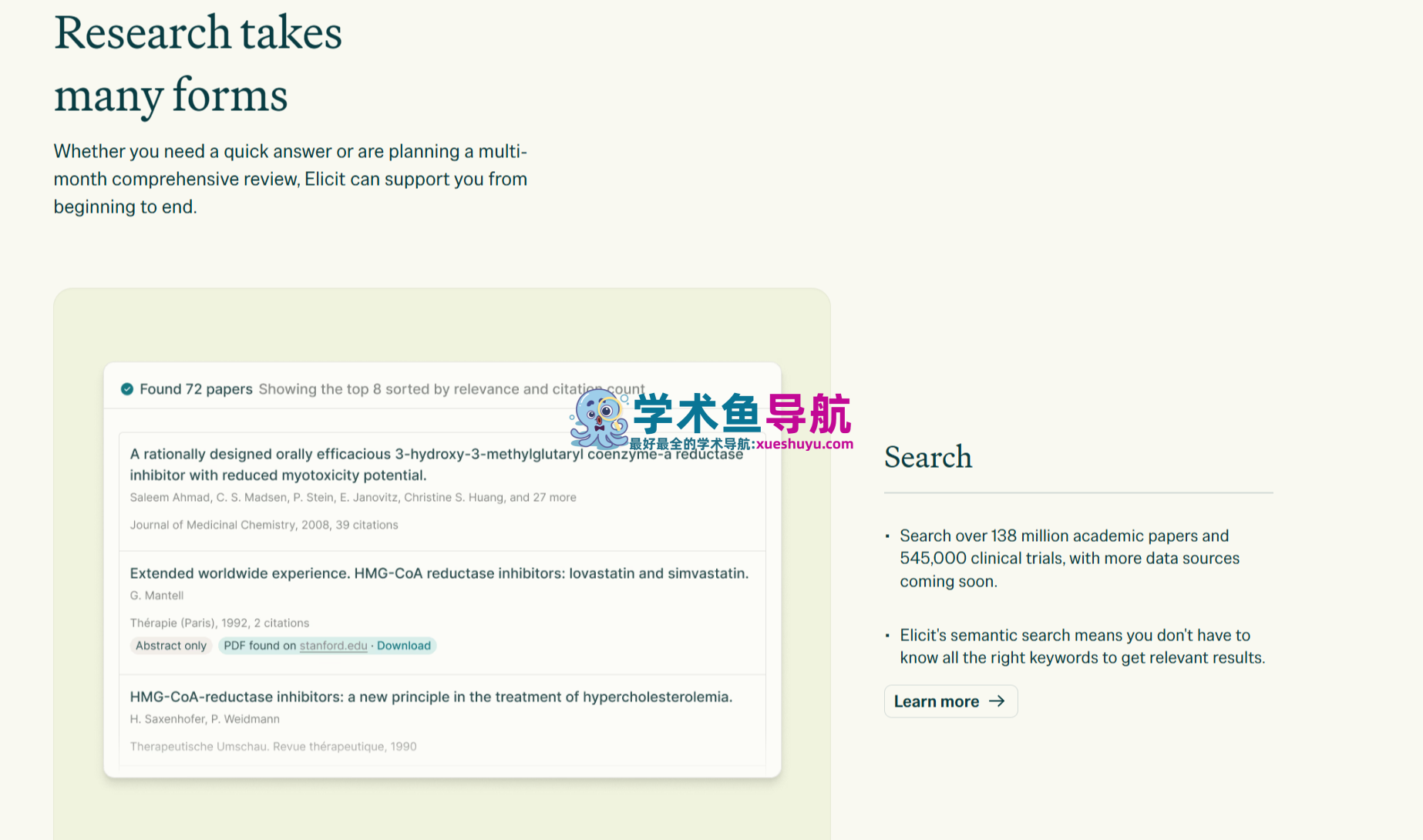
语义搜索:比关键词搜索更理解你的研究问题
Elicit的搜索引擎不是传统的关键词匹配系统。它使用SPLADE(Sparse Lexical and Dense Embedding,一种将稀疏词汇检索与稠密语义嵌入结合的混合方法)来理解研究问题的语义意图,而不只是匹配文本字符串。
实际效果是:输入”低剂量阿司匹林对老年人群心血管事件的预防效果”,系统不只是搜索包含这几个词的文章,而是能够识别出讨论”阿司匹林初级预防”、”抗血小板治疗与老年人风险”等相关表述的论文,哪怕这些论文没有使用完全相同的词汇。在用户反馈中,”语义搜索找到了我自己关键词搜索漏掉的重要文献”是最频繁出现的正面评价。
搜索结果以列表形式呈现,每条结果包含标题、作者、发表年份、期刊,以及最关键的——自动生成的单句核心结论(TLDR),帮助用户在不打开全文的情况下快速判断相关性。
支持从搜索结果直接开展对话——选中若干篇文献后,可以用自然语言问”这些研究的样本量差异有多大”或”有没有研究在亚洲人群中复现了类似结论”,Elicit在这批文献范围内进行跨文献推理并给出答案,同时标注具体引用来源。
数据提取(Data Extraction):Elicit最强的”超级武器”
这是Elicit与所有同类工具差距最大的核心功能,也是专业研究者选择付费的最直接理由。
数据提取允许用户建立一张结构化表格,对一批文献进行标准化的信息抽取。操作逻辑是:用户定义”列”(Column)——即需要从每篇文献中提取的信息字段,可以是标准字段(样本量、研究方法、干预措施、对照组、结果指标、随访时长、偏倚风险……),也可以是完全自定义的字段(如”该研究是否在中国人群中进行””文章是否报告了亚组分析结果”);Elicit随后对选定的每篇文献自动完成信息提取,以结构化表格形式呈现,每个提取值都附带原文引用片段和AI解释说明,让用户可以直接核查AI的信息来源是否准确。
这个功能的效率优势是惊人的。一项人工数据提取100篇文献的系统综述任务,传统上需要2-4名研究者工作2-4周;Elicit的自动提取可以在数小时内完成初稿,研究者只需核查和纠正,整体工时压缩比保守估计超过60%,官方披露的数据是节省高达80%的时间。
在准确率上,独立研究测试中Elicit的数据提取准确率约达90%(在标准化程度高的生物医学文献中表现最好),这个数字已经超过了很多人工编码人员在疲劳状态下的表现。需要补充的是,这个准确率对高度专业化的术语或复杂推断型问题会下降,完全依赖AI提取而不进行人工核查不是推荐的做法。
自定义列(Custom Columns)是数据提取中最灵活的部分。用户可以用自然语言描述想要提取的信息——比如”该研究是否使用了盲法设计(yes/no,并给出判断依据)”——Elicit会在每篇文献中查找对应信息,给出yes/no判断,并引用支持判断的原文段落。这种高度灵活的自定义能力,让Elicit可以适配几乎任何学科和任何系统综述设计的数据提取需求。
系统综述全流程工作流(Systematic Review)
这是2026年4月Elicit正式推出的旗舰功能,也是其产品进化的战略核心。系统综述工作流将整个PRISMA(系统综述和Meta分析优先报告条目)流程的主要步骤整合在一个引导式界面中:
第一步:研究问题精炼(Research Question Refinement)
用户输入初步研究问题,系统辅助拆解为PICO框架(Population人群、Intervention干预、Comparison对照、Outcome结局),提供结构化的研究问题描述建议,为后续检索建立清晰边界。
第二步:多源文献搜集(Gathering Sources)
系统基于精炼后的研究问题,自动执行多策略文献检索,包括Elicit数据库的语义搜索、以及支持手动上传PDF的私有文献补充。Pro版支持同时处理最多5,000篇候选文献。
第三步:标题与摘要筛选(Title & Abstract Screening)
这是系统综述中最耗时的人工环节之一。Elicit对每篇候选文献进行自动相关性评估,标注”纳入”、”排除”或”需人工判断”,并给出判断依据。研究者可以设定自定义筛选标准,系统依照标准执行,最终审核由研究者把关。
第四步:结构化数据提取(Data Extraction)
在通过标题筛选的文献上执行上述数据提取功能,批量填充研究者预设的提取表格。每个字段都有来源引用,支持追溯核查。
第五步:研究报告生成(Research Report)
基于所有提取数据,AI自动生成结构化研究报告,包含证据综合概述、关键发现摘要、研究质量评估和研究缺口识别。报告内容高度可定制——用户可以选择哪些部分包含在报告里、覆盖哪些文献、报告哪些提取维度的信息。
这个功能的战略意义在于:它让Elicit从一个”查文献的工具”变成了”做综述的平台”,覆盖的不是某一个环节,而是整个工作流的端到端闭环。
文档对话(Chat with Papers)
类似于其他AI工具的”与PDF对话”功能,但Elicit的实现方式有几个细节上的优势:
允许跨多篇文献同时进行问答,而不只是针对单篇PDF。免费版支持每次4篇同时处理,Pro版无限制。这意味着用户可以问”这三篇关于益生菌的研究,在样本人群上有什么差异”,系统跨文献综合给出结构化答案。
所有回答都有来源定位:系统回答中的每个关键陈述都附带原文引用段落(高亮显示),可以直接点击跳转至对应文献的对应位置进行核查。这种”可核查AI输出”的设计哲学,是Elicit在研究诚信立场上的具体体现。
支持上传私有PDF:用户可以上传自己的文献(包括付费墙后的文献PDF)进行分析,系统在私有内容基础上执行数据提取和问答,不局限于公开学术数据库的覆盖范围。
研究报告(Automated Reports)与图表提取(Figure Extraction)
Automated Reports:用户输入研究问题,系统自动执行搜索、筛选、提取,并生成一份结构化综述报告,整个过程无需逐步手动操作。报告的深度可定制:可以指定覆盖的文献范围、希望重点提取的信息维度、以及报告的详略程度。免费版每月2次报告额度,Pro版每年144次。
Figure Extraction(图表数据提取):这是Scale版的独有功能,2025-2026年正式推出。对于大量依赖图表呈现结果的研究领域(如基因组学、神经影像学、材料科学),文字形式的数据提取无法覆盖图表内的关键信息。Figure Extraction能够识别PDF中的图表,并从中提取数值数据、趋势描述或图例信息,将视觉数据转化为可提取的结构化内容。这是目前学术AI工具中极少数实现这项能力的产品。
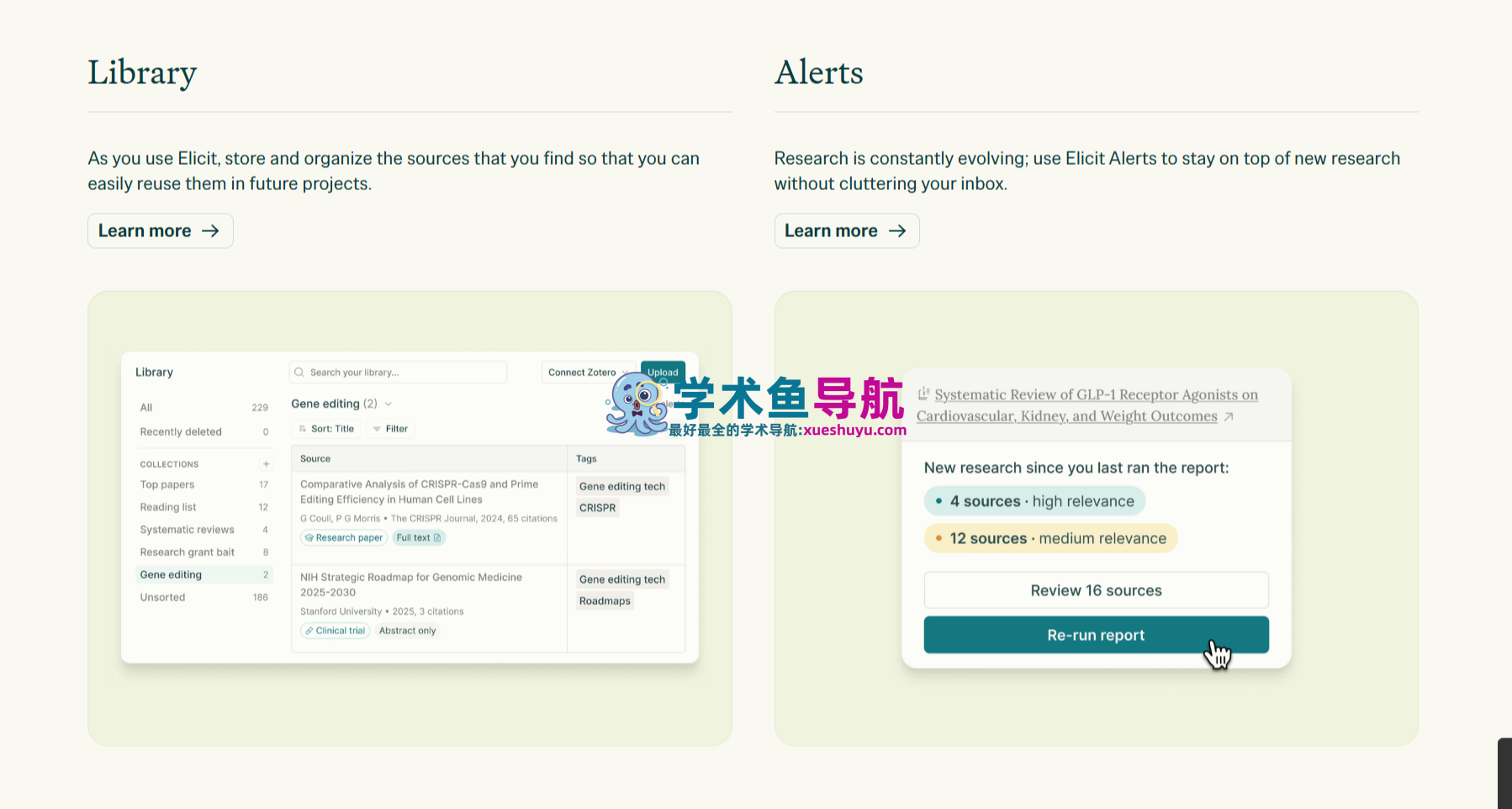
研究提醒(Research Alerts)
设定研究关键词或保存的搜索策略,Elicit定期扫描数据库更新,一旦有新发表的相关文献,自动发送提醒。这个功能类似于PubMed Alerts或Google Scholar alerts,但与Elicit的数据提取工作流深度集成——新提醒到达后可以直接将新文献加入现有的提取表格,无缝延续已有的综述工作。Pro版才有研究提醒功能。
Zotero集成与导出功能
Elicit支持从Zotero直接导入文献库,让用户将已有的文献管理系统与Elicit的分析能力打通。导出功能支持CSV(电子表格)、BIB和RIS格式,允许将提取的结构化数据和文献元数据无缝转入其他工具进行进一步处理。
Pro版的导出能力明显强于免费版——免费版的CSV导出受到提取次数的约束,无法满足系统综述级别的批量导出需求。
实测评价:优势与局限并陈
真实好用的地方:
数据提取功能的质量是同类工具中的绝对领先者。能够用自然语言定义提取字段、自动批量处理数百篇文献、每个提取值都有原文引用来源——这个组合在效率和可信度上同时领先,没有竞品能在这两个维度同时做到类似水准。
语义搜索的召回率明显高于关键词搜索。真实用户的反复反馈是:Elicit找到了用PubMed精心设计的布尔检索策略都遗漏的重要文献。这不是功能宣传,而是可以亲测验证的具体优势。
系统综述全流程工作流是目前市面上端到端覆盖最完整的AI系统综述方案。从研究问题精炼到最终报告生成,每个步骤都有AI辅助,研究者不需要在多个工具之间频繁切换,可以在一个界面内完成整个综述项目的大部分工作。
可信度设计是Elicit的产品底色。在AI回答正确率普遍不高的背景下,Elicit坚持每个AI输出都有来源引用和可核查路径,这让研究者能够放心地把AI作为”协作工具”而不是”黑盒子”。
需要正视的问题:
免费版的实际可用性相当有限。每月20次数据提取的上限,对于真实的文献综述场景远远不够,免费版更多是功能体验入口,而非可持续使用的工作方案。
对非英文文献的覆盖率偏低。数据库以英文学术出版物为主,中文文献(CNKI、万方)的收录量极为有限。对于需要大量参考中文文献的研究者,这是一个实质性的局限。值得注意的是,2026版本开始逐步扩展中文预印本数据库的覆盖范围,但距离对中文文献真正有价值还有明显差距。
社科、人文领域的文献提取效果弱于生物医学领域。Elicit的强项是在研究设计相对标准化(RCT、队列研究、实验研究)的实证领域——因为数据提取字段相对固定,AI对结构化程度高的文献处理更准确。对于质性研究、历史研究、文学研究等文本高度个性化的领域,提取准确率下降明显。
没有文献可视化功能。与Litmaps的引用网络图谱相比,Elicit完全没有引用关系的可视化呈现,在需要理解文献之间关系网络的探索性阶段,这是一个功能缺口。
不提供写作辅助功能。Elicit专注于”研究发现和证据提取”,不提供论文写作、润色或格式生成功能。对于需要一站式覆盖”读文献+写论文”全流程的用户,Elicit需要与SciSpace、Grammarly或其他写作工具配合使用。
Pro版定价较高。每月49美元(年付)对于预算有限的学生或独立研究者不够友好,与Mendeley完全免费、Zotero几乎零成本相比,这个价格门槛在系统综述需求不高频的情况下难以自证合理。
5款同类工具横向精讲
1. Consensus
Consensus是一款以”科学共识提取”为核心定位的AI学术工具,与Elicit的系统综述路径有明显的产品哲学差异。
核心优势: Consensus Meter是其标志性功能——对于特定研究问题,系统从文献中提取证据,以”Yes/No/Possibly”的共识度量化形式给出答案,并标注证据强度。这对于需要快速判断”科学界对某一问题是否有共识”的用户(政策制定者、科学记者、非专业研究者)极为直观。覆盖文献数量约2亿篇(基于Semantic Scholar);免费版每天10次搜索;回答格式简洁易读,不需要用户具备系统综述的专业知识。
核心劣势: 数据提取能力远弱于Elicit,不支持自定义列数据提取;没有系统综述工作流;回答深度有限,适合快速判断而非深度分析;对高度专业化的技术问题有时会过于简化,共识度判断可能误导没有背景知识的用户。
与Elicit的关键差异: Consensus是”快速答案”工具,Elicit是”深度分析”工具。如果你需要在5分钟内得到一个研究问题的概览性共识答案,Consensus更简便;如果你需要提取结构化数据用于正式系统综述,Elicit无可替代。两者面向的用户决策场景在时间维度上截然不同。
定价参考: 免费版每天10次搜索,Premium约每月10美元。
2. SciSpace(原Typeset)
SciSpace是一款同时覆盖文献阅读、AI问答和论文写作辅助的综合学术工具,与Elicit最大的区别在于它有成熟的写作支持功能。
核心优势: AI论文写作助手是SciSpace的核心差异化功能,支持从大纲生成到段落润色的完整写作辅助,这是Elicit完全不具备的能力;覆盖约2.8亿篇文献,数量超过Elicit;PDF阅读器内置AI解释功能,可以对选中段落进行即时解释和追问;支持150+种AI工具模式;期刊格式库完整,支持投稿格式一键适配。
核心劣势: 系统综述的专项数据提取能力弱于Elicit;自定义提取列的深度和准确率不及Elicit的精准表现;AI输出的来源标注透明度相对较低;系统综述全流程工作流的完整性不如Elicit。
与Elicit的关键差异: 如果你的工作是”读+写”全流程,SciSpace是更完整的一站式解决方案;如果你的工作是高质量系统综述的证据提取,Elicit专业深度领先。对于博士生和科研人员,两者经常被组合使用——Elicit做文献分析,SciSpace做写作辅助。
定价参考: 免费版功能可用,Premium约每月12美元,功能齐全版本更高。
3. Scite
Scite以”引用质量分析”建立独特定位,提供其他工具都没有的维度:追踪一篇文献的引用,到底是支持(supporting)、挑战(contrasting)还是仅提及(mentioning)它的核心结论。
核心优势: Smart Citations系统对每条引用进行类型标注,研究者可以快速了解一篇论文是否已被后来的研究质疑或推翻——这在循证医学中是极高价值的信息;Reference Check功能可以扫描你的稿件,标出已被推翻的引用;覆盖超过12亿条引用陈述;对生物医学文献的深度覆盖是同类中最好的。
核心劣势: 没有可视化文献关系功能;没有自动数据提取能力;没有系统综述工作流;数据库对非医学领域的覆盖率明显偏低;免费版功能受限很大;年费约$120,与Elicit Pro($588/年)相比更贵却功能更单一。
与Elicit的关键差异: Scite解决的问题是”我引用的这篇文献,它的核心结论是否经得起后续检验”;Elicit解决的问题是”从一批文献中系统性地提取结构化证据”。两者之间存在明确的互补关系——在需要做高质量系统综述的场景,Elicit处理数量,Scite做质量核查,组合使用是最佳方案。
定价参考: 免费版功能有限,Plus约$120/年,机构版面议。
4. Undermind
Undermind是近年兴起的一款AI学术搜索工具,采用基于智能体(Agent-based)的迭代式搜索策略,定位于需要深度覆盖某一研究方向的用户。
核心优势: 基于AI智能体的迭代搜索——系统不是执行一次搜索就结束,而是自动追踪每次搜索结果,识别新出现的相关概念和关键词,执行后续迭代搜索,直到搜索覆盖率趋于饱和;对于需要找到”所有相关文献”而不只是”最相关文献”的系统综述场景,这种迭代式深挖有独特价值;在某些领域的测试中,覆盖率高于Elicit的单次语义搜索。
核心劣势: 没有结构化数据提取功能;没有系统综述工作流;没有文献对话功能;产品相对年轻,用户基础和社区资源比Elicit小得多;定价较高且不如Elicit透明;对中文学术领域的覆盖同样极弱。
与Elicit的关键差异: Undermind在”确保搜索不遗漏”方面有独特优势,Elicit在”提取分析已找到的文献”方面独树一帜。两者的组合可以覆盖系统综述的检索端和分析端:用Undermind做全覆盖搜索,用Elicit做结构化数据提取。
定价参考: 按搜索次数计费,具体定价参照官网最新方案。
5. Litmaps
Litmaps(已收购ResearchRabbit)是以引用网络可视化为核心定位的文献发现工具,与Elicit代表了学术AI工具赛道的两种完全不同的产品路径。
核心优势: 交互式引用网络地图是文献发现效率最高的方式——以一两篇已知论文为种子,5分钟内生成覆盖数百篇关联文献的可视化地图;多维度轴向切换(引用量、Momentum、发表年份)让文献格局”一图读懂”;文献监控功能持续追踪领域动态;与Zotero的双向同步让发现和管理无缝衔接;学术用户定价极低(折扣后约$2-3/月)。
核心劣势: 没有结构化数据提取功能;没有系统综述工作流;文献发现后的”做什么”完全依赖其他工具;对中文文献覆盖同样极弱。
与Elicit的关键差异: 这是文献综述工作流的”前端”与”后端”的关系——Litmaps解决”发现文献”的问题,Elicit解决”分析文献”的问题。一个完整的高质量文献综述工作流,需要两者都有。推荐的使用顺序:用Litmaps可视化地图发现和确定文献范围,筛选出候选文献列表,导入Elicit进行结构化数据提取,最后生成系统综述报告。
定价参考: 免费版1张地图,Pro约$8-10/月,学术折扣后约$2-3/月。
横向对比速览
谁最适合用Elicit
开展系统综述和Meta分析的临床研究者与学术团队,是Elicit最典型也最高价值的用户群。无论是循证医学领域的Cochrane Review、临床实践指南的证据基础整理,还是学术期刊要求的系统综述论文,Elicit提供的自动化筛选和结构化提取能力,能将传统需要数月的综述工作压缩到数周甚至数天。对于每年需要开展多次系统综述的机构,Pro版49美元/月的成本与人工时间节省相比,ROI非常清晰。
在高强度文献阅读期间的博士研究生。在论文开题或撰写文献综述章节的阶段,Elicit可以快速建立一批候选文献的结构化证据表格,帮助研究者在深度阅读之前就有清晰的”领域证据地图”,大幅提升文献综述的系统性和完整性。免费版的20次月度提取配合限量使用,对轻度使用的学生可能够用;高强度使用者需要考虑升级。
医疗机构和政策研究机构的研究部门。需要定期整理某一议题的证据基础、追踪研究进展、并对决策者汇报证据摘要的团队,Elicit的Automated Reports功能可以大幅降低证据综述的制作周期。Scale版的团队协作功能让多人同时推进一个大型综述项目成为可能。
企业研发团队。制药公司的竞品分析、医疗器械公司的临床证据整理、科技公司的技术前景调研——这些场景都需要系统性地从学术文献中提取特定信息,Elicit的自定义提取字段能够适配几乎所有这类需求,Enterprise版的私有数据隔离和合规功能也满足企业级数据安全要求。
不太适合Elicit的情形:
以中文文献为主要来源的国内研究者——数据库覆盖的现实局限决定了使用价值有限。以质性研究、人文研究为主的学科研究者——非标准化文本的提取准确率明显偏低,AI提取的可信度不足以支持学术引用。只需要基础文献管理和引用格式生成的用户——Zotero和Mendeley的免费版完全够用,不需要Elicit的专项深度。预算有限且系统综述需求不频繁的学生——免费版的配额限制明显,Pro版的月费对低频用户来说难以摊薄成本。
关于”AI辅助系统综述的可信度”这个根本问题
Elicit是极少数主动在官方文档中讨论自身局限性的AI工具。它明确指出:系统综述工作流是加速研究的辅助手段,不能替代研究者的专业判断;AI提取存在错误率,所有AI输出都应该经过人工核查;对于高风险临床决策(如直接影响患者诊疗的指南制定),双人独立评审仍然是必要的;当前的准确率水平意味着Elicit最适合作为”半自动化的第二审查员”而不是完全替代人工审查的工具。
这种诚实性来自Ought公司的创始基因——他们研究的核心问题之一就是”如何让AI辅助系统行为透明、可核查、值得信任”。在AI工具普遍倾向于夸大能力的背景下,这种产品诚实性是一个值得珍视的品质,也是Elicit在学术社区建立信任的根本原因。
一项2025年底发表的同行评审研究(发表于社会科学类方法论期刊)实证检验了Elicit作为系统综述半自动化第二审查员的表现,结论是:Elicit可以有效补充人工审查流程,在标准化程度高的筛选任务中表现合格,但不建议作为唯一审查来源。这个学术评估与Elicit官方的表述高度一致,也是理解这个工具真实定位最好的外部参照。
Elicit、Litmaps与Consensus的最优组合使用方式
对于需要开展高质量系统综述的研究者,当前学术AI工具生态中最优的工作流组合如下:
阶段一:文献发现(Litmaps)
以已知核心论文为种子,生成引用网络可视化地图,识别领域内的高影响文献、前沿研究和潜在空白区域,建立候选文献集合。
阶段二:全覆盖搜索补充(Undermind或PubMed系统检索)
在Litmaps的发现基础上,用迭代式搜索或传统系统检索补充可能遗漏的文献,确保检索覆盖率。
阶段三:证据提取分析(Elicit)
将候选文献导入Elicit,使用自定义列执行结构化数据提取,自动化标题/摘要筛选,生成可以直接用于综述报告的证据表格。
阶段四:引用质量核查(Scite)
对纳入的关键文献进行引用质量检查,识别已被质疑的研究发现,确保综述的证据基础没有建立在已被推翻的结论上。
阶段五:报告写作(SciSpace或Grammarly)
在Elicit生成的结构化报告草稿基础上,用写作辅助工具完善论文撰写。
这个五阶段工作流的总成本(各工具学术版),远低于一次系统综述项目传统所需的人工成本,而覆盖的质量维度明显超过任何单一工具能独立提供的范围。这是当前学术AI工具生态协作使用的最佳实践框架。





