











Scopus官网:Elsevier旗下的全球最大同行评审文献摘要与引文数据库,涵盖科学、技术、医学、社会科学及艺术人文领域,提供全面的科研发现、分析与评价服务。
什么是Scopus?
Scopus是由爱思唯尔(Elsevier)于2004年推出的全球最大同行评审文献摘要与引文数据库,是目前全球规模最大的学术文献数据库之一。该平台收录来自5000多家出版商的超过2.9万种活跃期刊,涵盖自然科学、医学、社会科学、工程技术、人文艺术等27个学科领域,支持40多种语言,数据来源遍及150多个国家。Scopus的核心定位是”全球科研评价与文献检索的核心工具”,为学者、机构、基金资助者和政策制定者提供全面的科研表现评估和文献发现服务,是QS、THE、软科等全球知名排名机构用于大学排名和科研评估的重要数据源。
Scopus官网: https://www.scopus.com/pages/home

Scopus深度评测:爱思唯尔这把学术数据库王牌,在2026年的AI时代还值得信赖吗?
全球学术数据库的竞争格局,在过去三十年里呈现出一种奇特的二元结构:一边是科睿唯安(Clarivate)的Web of Science,凭借半个多世纪的历史积累和官方影响因子的垄断地位,维持着自己”老权威”的市场位置;另一边是爱思唯尔(Elsevier)于2004年推出的Scopus,以更大的期刊覆盖量、更现代的产品设计和更积极的功能迭代,持续向这个老权威发出挑战。
Scopus官方数据显示,截至2026年初,平台已收录超过1亿条文献记录,涵盖25,000+种活跃期刊、超过1960年至今的书籍章节、330万+会议论文,以及来自arXiv、bioRxiv等主要预印本平台的预印本文献。这个规模,使Scopus成为目前商业学术数据库中覆盖量最大的选手。
但”大”不等于”好用”,”有1亿条记录”也不等于”适合所有科研人员的工作流”。
2025年8月,Scopus推出了AI工具体系中迄今最重磅的功能更新——Deep Research,将Agentic AI(智能体AI)引入文献综述工作流,声称能在数分钟内生成原本需要数天完成的研究报告。与此同时,2026年3月的数据库更新中,Scopus在当月移除了7种未达标期刊,而2026年初荷兰多所大学(包括阿姆斯特丹自由大学、特文特大学)宣布终止Web of Science订阅的新闻,实际上为Scopus带来了一批重新审视的机构客户,因为很多机构在放弃WoS的同时,仍然保留或新订了Scopus。
这篇文章的目标是把Scopus的完整功能体系拆解清楚,从数据库架构到AI新功能,从CiteScore与JIF的底层差异到系统综述工作流中的真实表现,逐一给出判断,并与Web of Science、Google Scholar、Dimensions、Semantic Scholar、Elicit五款竞品做完整的横向比较。
Scopus是什么:爱思唯尔的”中立”学术索引战略
理解Scopus,必须先理解其定位中的一个刻意表述:“source-neutral”(来源中立)。
爱思唯尔是全球最大的学术出版商之一,旗下拥有Cell Press、Lancet、Tetrahedron等数百种高影响力期刊。从竞争逻辑上说,一个爱思唯尔旗下的数据库,理应在收录爱思唯尔自家期刊上有天然的优先性。Scopus对此的回应是:收录决策由独立的内容遴选与审查委员会(Content Selection & Advisory Board,CSAB)做出,爱思唯尔的编辑团队不参与收录与排除的决定。
这个结构性的独立机制,是Scopus维持学术公信力的关键安排,也是它在全球高校和科研机构中能够与Web of Science抗衡的公信力基础。如果Scopus被认为是爱思唯尔自家期刊的推广橱窗,它的引文指标就毫无参考价值——CSAB的独立性正是为了防止这种感知产生。
Scopus的内容遴选标准覆盖以下核心维度:
-
同行评审:申请收录的期刊必须发表经过同行评审的内容,且评审流程需有明确的公开说明
-
出版伦理:期刊需遵守COPE(出版伦理委员会)标准,无已知的伦理违规记录
-
引用规范:文章需包含规范的参考文献,且已发表论文可通过DOI或其他标准化方式访问
-
内容范围一致性:已发表文章与期刊声明的范围相符
-
定期性:期刊按照声明的出版频率稳定运营,不存在长期停刊或不规律出版的情况
-
编辑委员会多样性:编辑委员会成员具有真实的学术资质,且有足够的国际化代表性
通过初审后,期刊进入CSAB的正式评审,由学科专家小组从内容质量、期刊声誉、读者群体等维度综合评估。整个流程通常需要数月到一年时间。CSAB每季度进行更新(包括新增和移除决策),2026年初以来的每次更新都有公开的新增/移除名单。2026年3月的更新移除了7种期刊,其中6种是因为期刊本身已停刊(Discontinuation),1种因不符合持续遴选标准而被撤除。
数据库规模与内容构成
1亿+记录的具体来源分布
Scopus的1亿+条文献记录来自以下几个内容板块:
核心期刊文献(约9060万条):来自全球27,950+种活跃期刊(含7,270+种开放获取期刊)以及约7,500种非活跃(停刊)期刊。这个期刊覆盖数量是Web of Science Core Collection约20,000种期刊(SCIE+SSCI+AHCI合计)的约1.4倍,也是Scopus在覆盖广度上最大的量化差异。
会议论文:约330万+篇会议论文,来自全球主要学术会议的论文集,覆盖计算机科学、工程技术、物理等会议传统较深厚的理工科方向。
书籍章节:约一亿条记录中包含相当数量的书籍章节,覆盖Elsevier旗下出版书籍和合作出版商的专著章节,是Web of Science书籍覆盖(需订阅Book Citation Index)相对薄弱领域的补充。
预印本:通过与arXiv、bioRxiv、medRxiv、SSRN等主要预印本平台的内容合作,将预印本纳入检索范围,并在预印本最终发表为期刊文章时进行版本关联,避免同一研究的两个版本在引用计量上的混乱。
开放获取标识:Scopus对所有收录文献标注开放获取状态,细分为Gold OA(在完全开放获取期刊上发表)、Green OA(有合法的免费全文存档版本,通常是作者接受稿存档在机构库或PubMed Central)、Hybrid(在混合期刊上以开放获取形式发表)等不同类型,帮助用户在检索结果中直接判断文献的免费可获取性。
历史覆盖深度
Scopus的文献记录可以追溯到1788年,但完整的引用数据(包含参考文献链接)从1970年开始。1788年到1969年的文献以摘要和元数据为主,不包含引文网络数据——这意味着进行19世纪、20世纪前半段文献计量分析时,Scopus的数据不完整,在历史文献研究方向上不如Web of Science的Century of Science模块完善。

五大核心功能深度解析

一、高级搜索系统:比Web of Science更友好,比Google Scholar更精确
Scopus的检索界面是许多用户在Web of Science和Scopus之间明确表达”Scopus界面更好用”的主要原因之一,2025年初进行的Document Details页面重设计(Document Details page redesign)进一步改善了检索结果页面的信息组织。
文档检索(Document Search)
Scopus的Document Search支持以下核心字段的精确限定:
-
TITLE-ABS-KEY:同时在标题、摘要、关键词三个字段内检索,是覆盖最广的基础检索方式
-
TITLE:仅限标题字段,获得最精确的主题限定
-
ABS:仅限摘要字段
-
KEY:仅限关键词字段(作者关键词和索引关键词)
-
AUTH:作者姓名检索,支持多种格式变体和同名歧义处理
-
AUTHID:通过Scopus作者ID精确定位特定研究人员(解决同名歧义的最可靠方式)
-
AFFIL:机构名称字段,检索特定机构发表的文献
-
AFFILORG/AFFILCOUNTRY:机构下属组织/机构所在国家字段
-
SRCTITLE:来源期刊/书籍/会议名称
-
SUBJAREA:Scopus学科分类代码(覆盖27个一级学科大类,330+二级学科子类)
-
FUND-SPONSOR:资助机构字段,检索特定基金资助的研究成果
-
PUBYEAR:发表年份
-
DOCTYPE:文献类型(ar=期刊文章,re=综述,cp=会议论文,bk=书籍,ch=书籍章节等)
检索操作符
布尔操作符:AND、OR、AND NOT;近邻操作符:W/n(两个词之间最多n个词的顺序近邻)、PRE/n(限定词序的近邻);截词符:*(0到无限个字符)、?(精确1个字符);精确短语:引号括起。
二次检索与检索式组合
Scopus的检索界面维护本次会话的检索历史,每条检索式自动编号,可以对两个历史检索结果取交集(AND)、并集(OR)或差集(AND NOT),构建系统综述需要的复合检索策略。这个功能与Web of Science类似,但Scopus的界面反馈更清晰,操作逻辑对初学者更友好。
结果筛选与排序
检索结果页支持对以下维度进行筛选:年份区间、学科领域(ASJC分类)、文献类型(期刊文章/综述/会议论文/书籍章节)、来源期刊/会议、作者、机构、资助机构、国家/地区、语言、开放获取状态(只看开放获取文献)。排序支持相关度、被引次数(降序)、发表日期(最新/最早)三种主要方式。
检索结果的可视化分析
Scopus检索结果的分析功能(Analyze Search Results)是其相对Web of Science可视化更直观的地方:
-
年份趋势图:发文量随年份的折线图,直观显示某个研究方向的活跃度变化
-
学科分布图:发文量在各学科大类的分布饼图
-
期刊来源图:前20名来源期刊的横条图,快速识别该方向的核心刊物
-
作者分布:前25名作者的发文量排行
-
机构分布:前25名机构的发文量排行
-
国家/地区分布:发文量的地理分布热力图和排行
-
资助机构分布:该方向研究的主要资助来源
这些可视化分析可以批量导出为图片或数据文件,比Web of Science的类似功能在视觉呈现和导出友好度上普遍被用户评价更高。

二、CiteScore:Scopus的期刊评价指标体系
CiteScore是Elsevier于2016年推出的期刊影响力指标,专为Scopus数据库定制,是中国学术界部分语境下开始被接受的JIF替代或补充指标。
CiteScore的计算方法
CiteScore使用4年引用窗口(而非JIF的2年),计算公式为:某期刊最近4年内发表的所有文章,在同样的4年窗口内被Scopus数据库中所有来源引用的总次数,除以该期刊在这4年内发表的所有可被引用文献数量。
这一计算方法与JIF有三个核心差异:
第一,时间窗口更长:4年窗口比JIF的2年更稳定,对年度引用波动不那么敏感,对于引用积累较慢的学科(数学、人文、部分社会科学)更公平——这些学科的文章往往在发表2-3年后才开始被大量引用,2年窗口的JIF会系统性地低估它们的影响力。
第二,纳入文献类型更广:CiteScore的分子(被引次数)来自Scopus全量收录的引用,分母(可被引文献)包含同行评审文章、综述、会议论文、社论、短讯等多种文献类型;JIF分母只计入被认定为”可被引文档”(通常指研究性文章和综述),排除了社论、读者来信等,这种差异导致分母计算口径不同,直接影响指标数值的可比性。
第三,计算更透明:Scopus公开了CiteScore的计算所使用的全部引用数据(通过Scopus账号可以追溯到每一条引用记录),而JIF的原始引用数据的完整可访问性历来受到学术界的批评。
CiteScore Tracker:这是CiteScore体系的一个实用功能——每年的正式CiteScore于当年5月发布(基于上年数据),而CiteScore Tracker在全年持续更新,每月刷新当年迄今的引用数据,给期刊和研究人员提供一个当年CiteScore走势的实时预估。对于需要判断某本期刊今年影响力变化趋势的用户,Tracker提供了比年度发布更高频的参考。
Source Normalized Impact per Paper(SNIP):这是另一个Scopus提供的期刊指标,其设计逻辑是通过对不同学科领域引用习惯的差异进行标准化调整,使不同学科期刊的影响力可以跨学科横向比较——物理期刊和历史学期刊的引用习惯完全不同,SNIP通过标准化处理,使”这本物理期刊和这本历史学期刊相比,哪个更有影响力”这个问题在理论上变得可以回答。
Scopus分区(Quartile Ranking):与JCR分区(Q1-Q4)逻辑相同,Scopus对每个学科大类内的期刊按CiteScore排序,分为Q1(前25%)、Q2(26%-50%)、Q3(51%-75%)、Q4(后25%)四个区间。相当数量的中国高校和科研机构已经将Scopus分区纳入科研绩效考核体系,作为JCR分区的补充甚至替代参考。
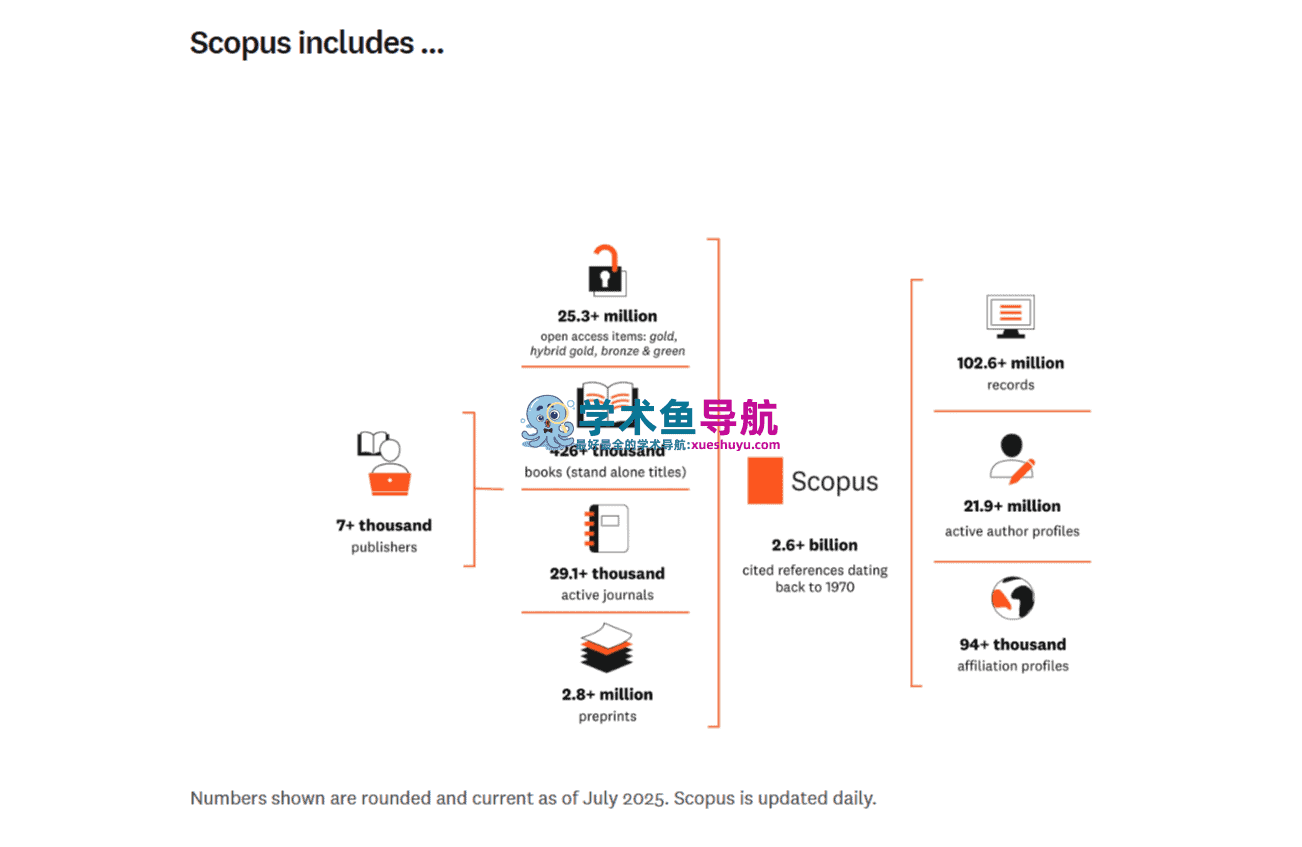
三、Author Profile(作者档案)与机构分析
Scopus的Author Profile(作者档案)是平台上超过1950万个可检索学者档案的集合,是学术圈进行人才评估、合作网络发现、科研人员影响力分析的重要工具。
作者档案的核心内容
每个Author Profile自动整合了该研究人员发表在Scopus收录来源上的全部文献,显示:
-
总发文量(期刊文章、综述、会议论文等分类统计)
-
总被引次数(Scopus数据库范围内的引用次数)
-
h指数(Hirsch指数,衡量研究产出数量与质量平衡的综合指标)
-
发文年份分布趋势图
-
主要合作者网络(合作次数最多的共著作者列表)
-
主要研究领域(基于发表文章的学科分类统计)
-
历年发表成果的期刊分布
-
机构归属历史(通过文章的作者单位信息自动追踪)
作者ID与ORCID整合
Scopus作者ID系统通过机器学习算法将不同文章中的同一研究人员归并到同一档案,同时支持与ORCID(国际学者识别码)关联。通过ORCID整合,研究人员可以一键认领或更正自己的Scopus档案,添加未被系统自动识别的文章,同时将Scopus引用统计数据同步到ORCID公开档案,提升个人学术档案在全球学术合作网络中的可见度。
机构Profile
类似于作者档案,Scopus为全球高校和研究机构建立了机构档案,统计机构的发文量、总被引次数、高被引论文数量、主要合作机构等信息。对于高校科研管理部门评估全校学术产出,或者参考某机构的学术实力进行合作选择,机构档案提供了一个数据视角。
四、Scopus AI(含Deep Research):2025年最重磅的产品跃升
Scopus AI是Elsevier在2024-2025年持续重投的AI战略产品,整合在Scopus主平台中,于2025年初开始向机构订阅用户全面开放。
基础Scopus AI:自然语言检索与研究摘要
基础Scopus AI功能允许用户以自然语言(而非检索式)提问,系统从Scopus数据库中检索相关内容,生成结构化的研究概述。关键特性:
-
每一个AI生成的陈述都附有对应的Scopus文献来源引用,确保内容可溯源
-
支持中文和多语言输入(虽然英文效果最佳)
-
自动识别研究领域内的主要研究主题、争议焦点和潜在研究空白
-
可以针对文献摘要进行追问(通过Copilot功能),对复杂或专业性极强的查询进行深入处理
2024年8月:Copilot功能
Copilot是针对高度专业化或复杂查询的优化功能,综合使用关键词检索和向量搜索(语义相似度检索)两种技术,提高对专业性强、描述性不精确问题的检索和回答质量。
2025年8月:Deep Research——迄今最重大的AI更新
Deep Research是Scopus AI体系的里程碑式更新,核心是将Agentic AI(智能体AI)的多步推理能力引入文献研究工作流:
Deep Research的工作流程分为以下步骤:
第一步,问题分解(Query Decomposition):用户输入研究问题后,Deep Research的推理引擎不是直接执行单一检索,而是将复杂问题分解为多个子问题,并独立为每个子问题制定检索策略。这个”多轨检索”机制使Deep Research能够处理那些单一关键词检索无法覆盖全部相关角度的复杂、跨学科研究问题。
第二步,多维证据收集:对每个子问题独立检索Scopus数据库,收集来自不同方向的证据,而不是只检索最显而易见的核心方向。
第三步,意外关联发现(Unexpected Connections):在综合多轨检索结果时,Deep Research算法会主动识别不同研究方向之间的潜在关联——即”你可能不知道A领域的研究对你的B领域问题有参考价值”这类洞察,这是人工手动检索很难系统性发现的隐性知识连接。
第四步,生成结构化报告:Deep Research输出一份包含以下板块的综合研究报告:
-
直接回答(Direct Answers):对研究问题的核心答案,注明使用范围和前提假设
-
意外关联(Unexpected Connections):跨领域的隐性关联发现
-
研究局限与空白(Research Limitations and Gaps):现有研究尚未充分解答的问题,直接为研究方向提供创新空间的识别支持
报告中的每个陈述都有Scopus来源文献的标注引用,用户可以一键跳转到原始文献进行深度阅读。
2026年初的使用体验:基于多名用户的反馈,Deep Research在以下场景表现突出:跨学科研究方向的全景梳理(比单一领域专家的直觉视角更全面);识别某个研究方向内部不同技术路线之间的比较证据;快速生成PhD论文或基金申请书中文献综述章节的初步结构框架。主要局限是:对于极度专业细分的研究方向(如特定蛋白质的特定修饰方式对某种癌症细胞信号通路的影响),过于细分的问题有时返回的是相关但不精确的内容,需要结合人工判断进行二次筛选;报告的生成时间(数分钟到十几分钟不等)比传统关键词检索慢很多,不适合需要快速响应的实时信息查询。
AI功能的机构订阅要求
Scopus AI(包括Deep Research)目前不对个人用户单独开放,需要通过机构订阅访问。2025年5月开始,越来越多的大学图书馆(包括波兰、荷兰、英国的多所大学)在Scopus机构订阅协议中加入了Scopus AI模块的访问权限。对于没有机构Scopus订阅的个人研究人员,这个功能暂时无法使用。
五、文献计量与引文分析工具
Scopus的引文分析能力是其与Web of Science正面竞争的核心战场,在某些具体维度上已经超越Web of Science,在另一些维度上仍有差距。
被引分析(Citation Overview)
每篇文章的被引分析显示:各年度被引次数的逐年柱状图、总被引次数(含和不含自引的两个版本)、直接链接到所有施引文献的列表。这个功能与Web of Science的”Times Cited”功能高度类似,但Scopus的界面更直观,被引次数的年度分布图显示在文章详情页的显著位置,不需要额外点击进入。
Altmetric整合
Scopus与Altmetric的合作整合是其相对Web of Science的明显优势点之一。Altmetric跟踪文章在Twitter/X、新闻媒体、政策文件、Wikipedia、博客等非传统学术平台的被提及情况,为研究人员提供传统引文指标之外的”社会影响力”视角。每篇Scopus文章详情页都显示该文章的Altmetric分数,让研究人员可以看到一篇文章是否超出学术圈、在更广泛的社会对话中引发了关注。
SciVal整合
SciVal是Elsevier旗下的研究分析工具,与Scopus深度整合,主要面向高校科研管理和机构战略分析。SciVal提供:机构学术产出的横向对比(与竞争机构的发文量、被引次数、合作网络的系统性比较);研究方向的战略定位分析(机构在特定学科方向的相对优势识别);科研人员绩效评估报告。SciVal的数据底层是Scopus,是Scopus在机构决策支持方向上的延伸应用。
期刊收录机制与”Scopus认证”的含义
对于中国学术界,Scopus的期刊收录认证具有几个层面的意义,需要分开理解:
Scopus收录 ≠ SCI/SSCI收录
在中国学术界,”SCI期刊”(指被Web of Science的SCIE收录的期刊)仍然是最被普遍采用的论文质量认证。Scopus收录的期刊数量(27,950+种)远多于SCI收录期刊数量(约9,500种),这意味着大量被Scopus收录但不被SCIE/SSCI收录的期刊——这些期刊在科研考核中通常被认定为”Scopus期刊”而非”SCI期刊”,两者的认可度在不同机构的考核标准中差别很大。
Scopus在中国的接受度正在上升
教育部和各高校对”Scopus收录”的接受度近年来持续提升,在不少机构的绩效考核中,”发表在Scopus收录期刊上”已经是有效的成果认定标准,特别是在会议论文方面(计算机科学等学科的顶级会议论文主要通过Scopus而非SCI索引)。但在医学、化学、物理等传统”SCI优势学科”,SCI认证的地位仍然高于Scopus。
中国期刊的Scopus申请流程
Scopus专门设立了Scopus中国学术委员会(CSAB China),专注于处理中国大陆期刊的收录申请,流程分为:自检(期刊对照Scopus最低收录标准自查)→预评估(通过CSAB中国学术委员会办公室提交预审)→正式申请(预审通过后自动进入正式流程)→Scopus团队验证→CSAB委员终审→结果通知(通过或不通过并告知原因)。整个流程通常历时6-12个月。
定价体系:机构订阅为主,个人准入极为有限
Scopus的商业模式与Web of Science基本相同——面向高校、研究机构、政府科研部门的机构年度订阅,定价为不透明的谈判制。荷兰SURF联盟(代表荷兰高校的联合采购组织)2025年1月签署的Scopus框架协议合同文件显示,机构年度许可费是一次性支付的统一费用,具体金额根据机构FTE规模在框架协议体系内协商确定。
定价参考范围(根据公开信息推算):
-
小型机构(< 5,000 FTE):约$5,000-$25,000/年
-
中型机构(5,000-20,000 FTE):约$25,000-$80,000/年
-
大型综合性研究型大学:可能超过$100,000/年
SciVal等高级分析模块通常作为附加订阅另行收费,Scopus AI功能的访问权限是否包含在基础订阅中,各机构的合同条款有所不同。
个人访问的有限选项
Scopus对个人用户的访问政策极为有限,没有面向个人用户的完整订阅选项。以下是个人用户可以访问Scopus的主要方式:
-
机构访问:通过所在机构(高校、研究院)的订阅许可访问,是绝大多数活跃研究人员的主要访问途径
-
Author Profile的有限免费访问:未订阅用户可以查看作者档案的基本信息(作者姓名、发表文章列表标题)和部分文章的摘要,但无法使用检索功能、引文分析或下载完整结果
-
Scopus官方提供的免费预览(Preview):可以进行有限次数的检索,查看检索结果条数,但不能看到详细记录
实测评价:Scopus的真实使用体验
真实好用的地方:
广于Web of Science的期刊覆盖,在实际使用中的最大体现是:在Web of Science中搜索不到记录的新兴期刊论文、地区性学术期刊文章、部分开放获取期刊的早期文章,在Scopus中往往可以找到。对于做跨学科研究、关注新兴领域、或需要覆盖非英语主导学科文献的研究人员,这种覆盖差异在文献查全率上有实质性影响。
可视化分析的导出友好性在用户反馈中持续获得正面评价。检索结果的学科分布、年份趋势、国家分布等可视化图表,在Scopus中支持直接导出为CSV或图片,且图表的视觉设计比Web of Science更现代,更适合在演示文稿或报告中直接使用而无需额外加工。
Scopus AI Deep Research的文献综述辅助能力,对于需要快速建立陌生研究方向全景了解的场景(如博士生在确定研究方向初期的文献调研、科研管理人员评估某个方向的研究成熟度)有真实的效率价值。生成的报告不只是文献摘要的拼接,而是有主题结构的证据综合,且每个陈述都有可追溯的Scopus文献来源,这在学术可信度上是决定性的优势。
开放获取标识系统让研究人员在检索结果列表中直接知道哪些文章有合法的免费全文版本,不需要逐篇尝试访问,显著降低了”找不到全文”的挫折感——特别是在2025-2026年开放获取政策快速推进的背景下,越来越多的文章有免费版本,Scopus的分类标识帮助研究人员快速找到这些资源。
需要正视的问题:
没有官方JIF/JCR数据是Scopus在中国学术考核体系下最根本的局限。CiteScore不能替代JIF在中国机构绩效考核中的法定地位,研究人员使用Scopus进行期刊选择时仍然需要单独到JCR系统确认目标期刊的影响因子,这是一个持续存在的工作流断点。
AI功能对个人用户完全关闭,这与付费门槛本身无关,而是在功能层面对没有机构订阅的科研人员的系统性排斥。在AI写作工具已经高度普及的2026年,一个只有机构用户才能使用AI辅助功能的商业数据库,面对的是越来越高的用户迁移压力——特别是当Elicit、Semantic Scholar等免费或低价工具提供了相当甚至更好的AI功能时。
引文数据的历史覆盖(1970年以前无引用数据)对做学科历史研究、或者需要追溯1950-1960年代奠基性文献引用关系的研究人员是真实的功能缺口,无法用覆盖更广的补救措施弥补——引用关系的历史数据要么有要么没有,无法替代。
5款同类产品横向精讲
1. Web of Science
Web of Science是Scopus在全球学术数据库市场的最直接竞争对手,两者共同占据着商业学术引文数据库市场的主导位置,在全球大多数研究型大学的图书馆中被同时订阅。
核心优势(相对Scopus): 官方JIF/JCR数据的独占权是Web of Science最不可撼动的核心护城河——影响因子这个指标本身就是由尤金·加菲尔德发明并通过JCR发布的,JCR是影响因子的唯一权威来源,这个事实在中国学术考核体系和全球大多数机构的绩效评估体系中具有结构性的法定地位;ESI(基本科学指标)的高被引科学家和高被引论文认证是目前全球认可度最高的学术人才量化评估标准;High Cited Papers和Hot Papers质量标识帮助快速识别领域重要文献;历史引用数据覆盖1900年以来(含Century of Science模块);SCIE/SSCI/AHCI的”精选”策略使数据库内期刊的平均质量密度更高。
核心劣势(相对Scopus): 期刊覆盖量(约20,000+种)小于Scopus(27,950+种),对新兴学科、区域性期刊、开放获取新刊的纳入速度更慢;可视化分析的导出友好度普遍被评为低于Scopus;AI功能(Literature Review 2.0)在技术路线上与Scopus AI类似,但推出时间略晚,目前综合能力评分与Scopus AI相当;多所欧洲顶校近年以成本效益为由终止订阅,价格问题更尖锐。
与Scopus的关键差异选择依据: 需要官方JIF/JCR数据、ESI高被引排名、1970年以前的历史引文数据→Web of Science;需要更广的期刊覆盖(新兴期刊、区域期刊)、更好的可视化导出、Altmetric整合→Scopus;系统综述指南通常建议同时检索两者以最大化查全率。
2. Google Scholar
Google Scholar是全球使用最广泛的免费学术搜索引擎,以海量覆盖和零成本使用为核心竞争力,覆盖约3.99亿篇文献。
核心优势(相对Scopus): 完全免费,无需注册,无机构订阅要求,对世界上任何地方的任何人开放;覆盖量(约3.99亿篇)是Scopus(约1亿)的4倍,包含学位论文、技术报告、白皮书、会议摘要等大量灰色文献;对于发现某篇文章的最新被引情况(包括在博客、工作论文等非正式渠道的引用),Google Scholar通常给出比Scopus更高的被引次数;Google Scholar个人主页允许研究人员免费建立可公开访问的学术档案。
核心劣势(相对Scopus): 没有高级检索字段和布尔逻辑的完整支持;没有期刊质量过滤机制,检索结果包含来自掠夺性期刊等低质量来源的内容;不提供CiteScore、JIF等期刊指标信息;没有系统性引文分析工具;没有AI文献综述功能;数据透明度低(不公开收录标准和更新机制);批量数据导出功能极为有限。
与Scopus的关键差异选择依据: 快速文献发现、不受机构IP限制的自由使用、灰色文献覆盖→Google Scholar;精确系统综述检索、引文计量分析、期刊质量评估、AI辅助文献综述→Scopus的可控检索和数据质量保障不可替代。
3. Dimensions(数字科学)
Dimensions是近年来增长最快的学术数据库,由Digital Science开发,覆盖约1.47亿条文献记录,并整合了学术文献之外的专利、临床试验、科研资助、政策文件等多类型研究生命周期数据。
核心优势(相对Scopus): 基础功能完全免费,对没有机构订阅的个人研究人员的可及性远优于Scopus;文献覆盖量(1.47亿)大于Scopus(1亿);专利、临床试验注册记录、科研资助数据库的整合,使研究人员可以在一个平台追踪从基础研究到应用专利到临床试验的完整知识转化链条;对人文社科和非英语文献的覆盖比Scopus更广;界面设计相对现代,基础操作的学习曲线更低。
核心劣势(相对Scopus): 没有CiteScore、JIF等期刊评价指标体系;引文数据的严格性不如Scopus,更广的收录范围伴随着更宽松的内容质量标准;没有Scopus AI Deep Research这样的AI文献综述工具;没有Author Profile的完整系统;没有与Altmetric、SciVal等周边工具的深度整合;付费版(Dimensions Plus)的定价同样不透明。
与Scopus的关键差异选择依据: 需要整合文献/专利/临床试验/资助数据的研究全链条分析、个人免费使用、更大的文献覆盖量→Dimensions;需要高质量精选文献、CiteScore期刊评价、Author Profile引用分析、AI文献综述→Scopus的数据质量控制和工具深度更优。
4. PubMed/MEDLINE
PubMed是美国国立医学图书馆(NLM)维护的生物医学文献权威数据库,是医学、公共卫生、生命科学领域最重要的免费文献检索平台,收录超过3500万篇文献。
核心优势(相对Scopus): 完全免费,无需注册;MeSH(医学主题词)体系是生物医学文献语义检索的全球标准,使用MeSH的精确检索在医学文献的查准率上优于Scopus的关键词检索;对生物医学文献的专项深度覆盖(包括护理学、牙医学、公共卫生等细分医学学科的期刊收录密度)高于Scopus;与PubMed Central(PMC)整合,大量文献可直接获取开放获取全文;对临床试验和系统综述文献类型的专项优化(Clinical Study Categories等过滤器);在医学领域系统综述中是不可绕过的必检数据库;中国大陆访问完全稳定(NCBI服务器,国内可直接访问)。
核心劣势(相对Scopus): 覆盖范围限于生物医学相关学科,工程、物理、化学、社会科学等学科覆盖极少;没有期刊CiteScore指标;没有AI文献综述功能;没有机构/作者引文分析工具;没有期刊搜索和期刊选刊功能;可视化分析功能极为有限;文献记录中的被引次数不如Scopus完整。
与Scopus的关键差异选择依据: 生物医学领域系统综述、需要MeSH精确检索、完全免费使用、临床研究文献专项检索→PubMed不可绕过;非医学学科文献检索、期刊质量评估、引文分析、AI文献综述、机构产出评估→Scopus。
5. Elicit
Elicit是由Ought基金会开发的AI辅助文献研究工具,是Scopus AI Deep Research功能在”AI原生”方向上最直接的竞争者,代表了”以AI能力为核心、数据库为支撑”的产品逻辑与Scopus”以数据库为核心、AI为增强”的传统逻辑的正面竞争。
核心优势(相对Scopus): 自动文献筛选和数据提取是Elicit的核心差异能力——基于用户定义的纳入/排除标准,自动对大量文献进行初步分类筛选,并从每篇文章中自动抽取样本量、实验条件、主要结果等字段,形成可以直接用于Meta分析的结构化数据表格,这个功能Scopus目前还没有对应替代;AI能力更新速度快,Elicit的AI功能迭代频率远高于Scopus;个人用户可以以较低成本($12/月起)购买高级功能,不需要机构订阅;与Zotero等文献管理工具的集成;没有平台自身的商业利益影响(Elicit不是学术出版商,其推荐结果不存在来源偏见)。
核心劣势(相对Scopus): 没有CiteScore、期刊分区等期刊评价指标;没有Author Profile和机构引文分析工具;文献覆盖的质量控制机制不如Scopus系统(Scopus有CSAB独立审核,Elicit的底层数据库Semantic Scholar没有同等级别的内容筛选标准);没有Altmetric、SciVal等周边生态;AI生成内容偶发幻觉问题需要人工核实;国内访问需要科xue+_$%上罔;对中文文献的支持有限。
与Scopus的关键差异选择依据: 系统综述数据提取和自动筛选(Meta分析前期工作)、需要以较低成本使用AI文献功能的个人研究人员→Elicit的AI原生能力和个人可购买性更有优势;期刊质量评估、Author Profile引文分析、机构产出评估、需要商业级别的数据质量保障→Scopus的成熟数据体系和生态整合不可替代。
横向对比速览
Scopus在2026年的精确竞争优势与使用逻辑
Scopus在2026年的市场位置,可以用一个坐标系来描述:它站在”权威+覆盖”这个坐标轴的中间偏右位置——比Web of Science覆盖更广、比Google Scholar质量更可控;站在”AI能力”这个坐标轴的中间位置——比传统工具强,比Elicit等AI原生工具弱;站在”可及性”坐标轴的左侧——高质量功能主要锁在机构订阅门槛后面,特别是AI功能。
Scopus真正不可替代的场景是:需要同时满足”覆盖量”和”数据质量控制”两个要求的系统综述;需要CiteScore期刊评估体系(特别是在JIF不够用、需要多指标互补的场景);需要Author Profile为基础的学者学术档案建设和合作网络分析;需要Altmetric整合的全渠道影响力评估;机构学术产出评估中需要与SciVal联动的决策支持。
Scopus正在被替代的场景是:个人研究人员的日常快速文献发现(Google Scholar、Semantic Scholar更轻便);系统综述的AI辅助数据提取(Elicit在这个具体场景更专业);没有机构订阅时的学术工具需求(Dimensions的免费覆盖提供了大部分文献发现功能)。
2025-2026年间,Scopus AI Deep Research的推出是Elsevier向这个替代趋势最直接的反击——把AI文献综述能力整合进权威数据库,试图打造一个”可信AI+全覆盖数据”的不可拆分组合。这个策略的执行质量,以及Scopus AI能力相对Elicit的差距是否会持续收窄,将是决定Scopus中长期市场竞争力最关键的变量。





